Normalization
Data scientists need to use normalization to organize the columns (attributes)
and tables (relations) of a relational database and reduce data redundancy and
improve data integrity.
To reduce potential errors and increase data efficiency, I always create a
database by using third normal form (3NF). There's no need to have duplicates in
your database, and it will take more space and increase data analyzing time.
Types of normalization:
1. First Normal Form (1NF): Doesn't contain duplicate rows; and every cell contains only one value.
2. Second Normal Form (2NF): If it's in first normal form (1NF); and every non-prime attribute of the
table is dependent on the whole of every candidate key.
3. Third Normal Form (3NF): If it's in second normal form (2NF); and every non-prime attribute is
non-transitively dependent on every candidate key.
Normalization Case
This is an example of how I examine a database and then normalize it.
This online shop transaction database is in first normal form (1NF), then I changed it
to second normal form (2NF) and third normal form (3NF). Here are several steps
that I did to normalize it.
Steps:
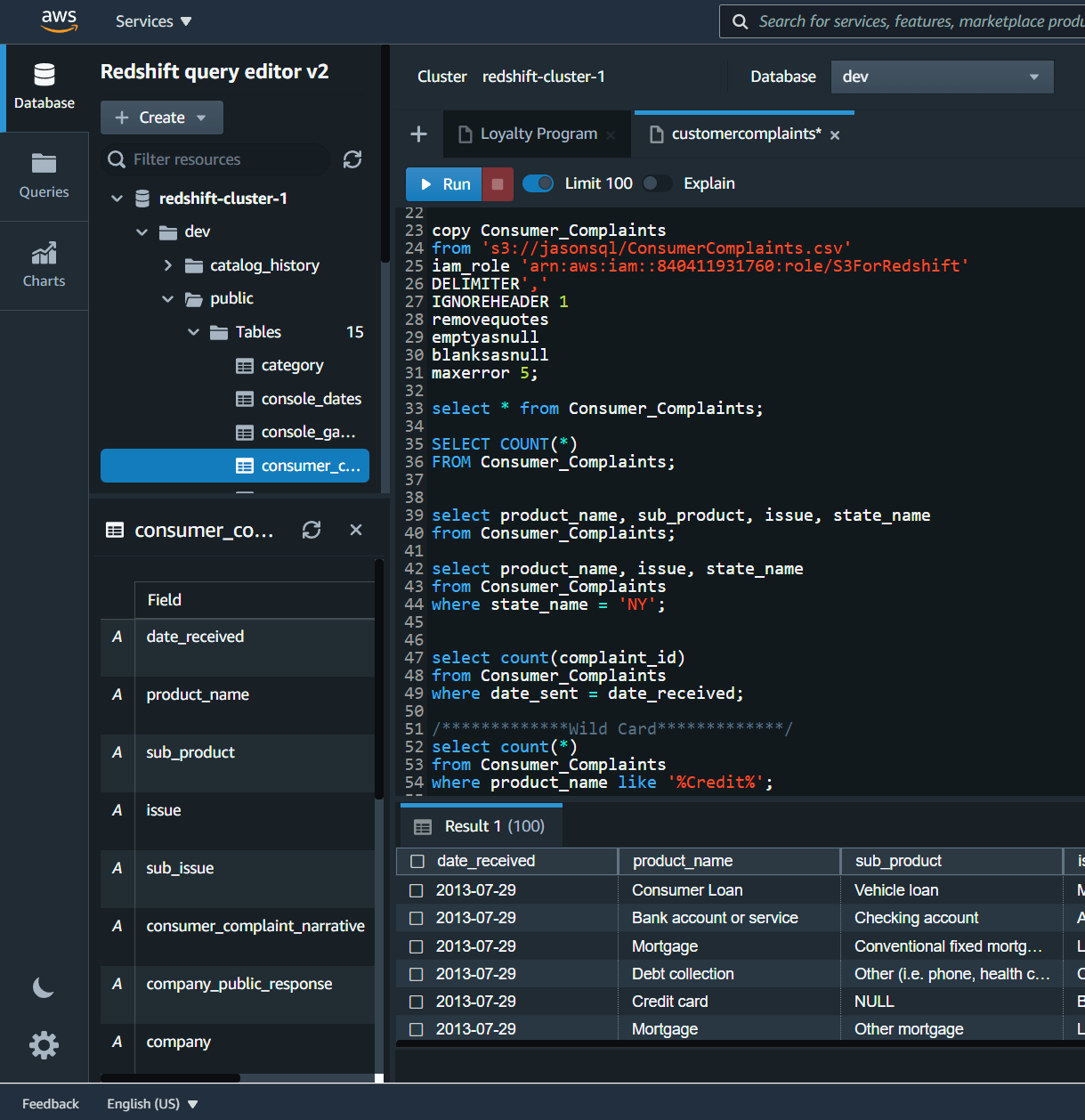
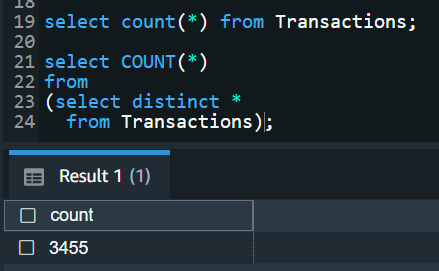
1. Check if it's in first normal form (1NF).
I checked if there are duplicated rows in the
database by running the following query so that I can see the total numbers of rows are the total
numbers of distinct rows. They matched, so it's in first normal form (1NF).
2. Check if it's in second normal form (2NF).
I need to find the candidate key, prime and non-prime
attributes in this database. The transaction id is the most obvious primary key and candidate key, but there
is more than one candidate key. To find the candidate keys in the database, I first think of the purpose of
this database. Because it's a database to record every transaction, so purchase time and customer id make up
the other candidate key. The first three columns are prime attributes and the rest columns are non-prime attributes.
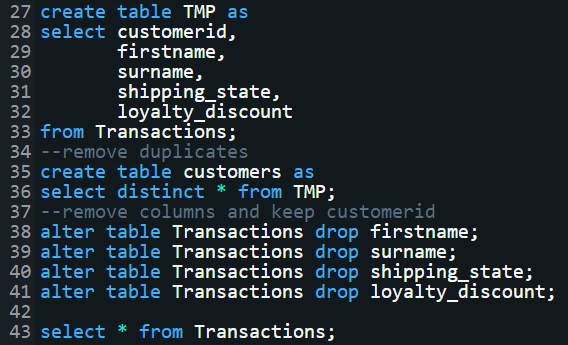
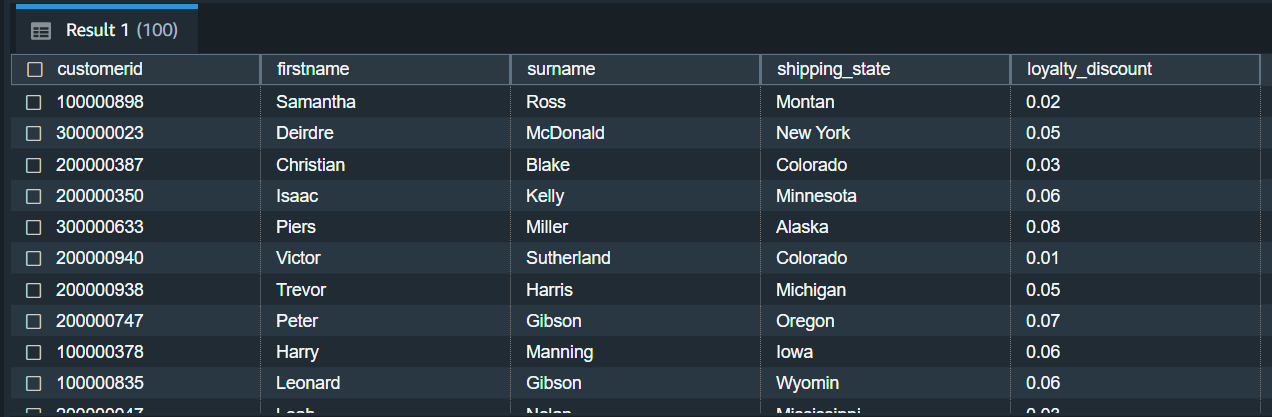
Then I found that customer id is sufficient to identify the first name, second name, shipping state, and loyalty discount. It's not
in second normal form, so I dropped these columns and create a separate table for these attributes.
I selected the unique customer rows and created another table. Then I dropped those columns
in the original table (Couldn't drop multiple columns at once in Redshift). Now, this database is in
second normal form (2NF).
3. Check if it's in third normal form (3NF).
Because I created a new table in the last step, I had to check two tables in this step.
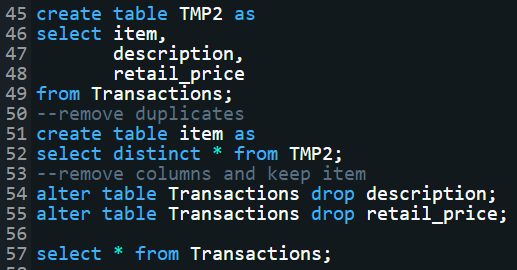
The customer table is in third normal form (3NF), but the modified transaction table is not
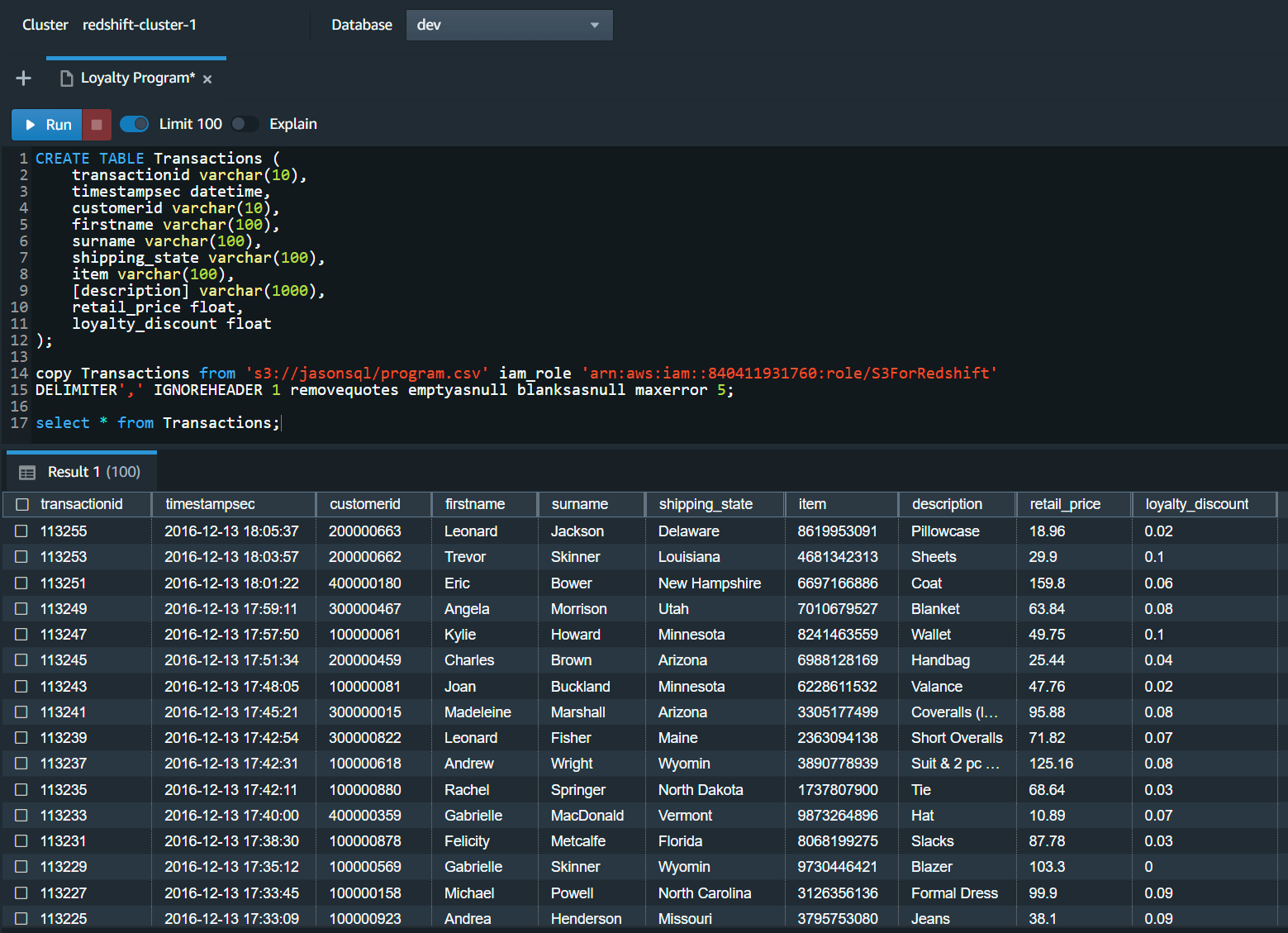
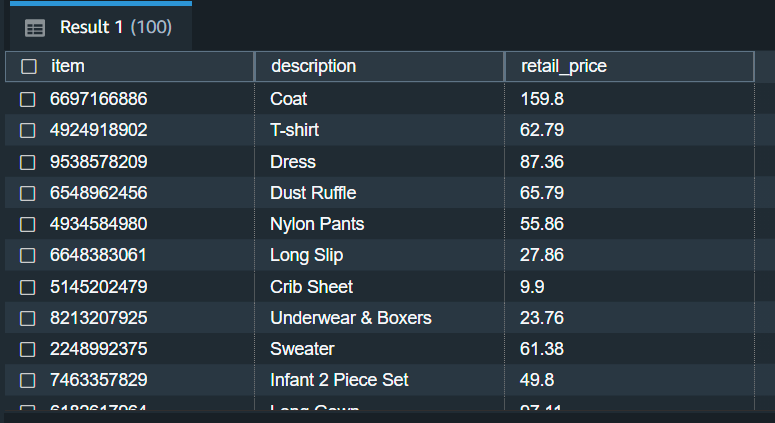
in third normal form (3NF). The description and retail price columns are dependent on the item column.
So split this table into two tables. The process is the same as the last one. I created another table
for the item, description, and retail price, then I dropped the description and retail price from the original table.
4. Results
Now there are three tables, but I removed many unnecessary duplicated rows.
It's not obvious in this example, but if a database contains billions of records, a database
in third normal form (3NF) is much more efficient.