Data scientists deal with big data by using Spark which is very powerful and user-friendly.
Spark 2.0 has shifted towards a dataframe syntax which is just like pandas and Spark's MLlib
library is similar to sklearn library. You also can write SQL queries by using Spark. Since I've had
many machine learning and SQL projects, I used Spark MLlib to create a spam filter in this Natural Language Processing project.
Why I choose Spark
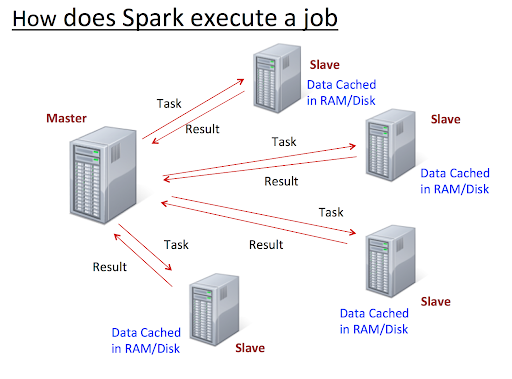
Spark is 100x faster than Hadoop Mapreduce.
Here are several reasons:
1. MapReduce writes most data to disk after each map and reduce operation
2. Spark keeps most of the data in memory after each transformation
3. Spark can spill over to disk if the memory is filled
At the core of Spark is the idea of a Resilient Distributed Dataset (RDD)
Here are several advantages of RDD.
1. Distributed Collection of Data
2. Fault-tolerant
3. Parallel operation - partioned
4. Ability to use many data sources
My Environment
There are many platforms to utilize Spark, such as databricks, AWS EC2, AWS EMR, Oracle VirtualBox.
I selected to use Pyspark on Ubuntu, a Linux system, running on Oracle VirtualBox. The platform
doesn't really matter. The example below is a SQL query by using Pyspark SQL.
NLP Spam Filter
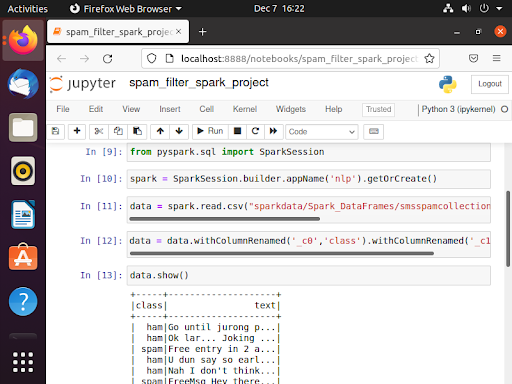
In this NLP project, there is a cleaned dataset that has two classes, ham and spam. I used findspark to locate Spark and created a spark session at the beginning.
Transform Features
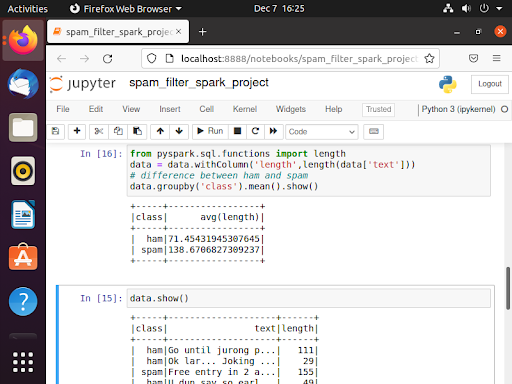
Technically, I only had one feature which is the emails, so I had to create some features here.
It's easy to find out that the lengths between ham and spam emails are significantly different.
I used this as the most important feature to classify spam emails. In practice, I should've transformed
more features to increase the accuracy, but this is just a Spark example.
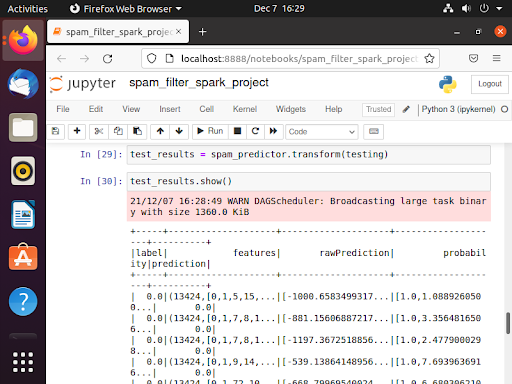
NLP Results
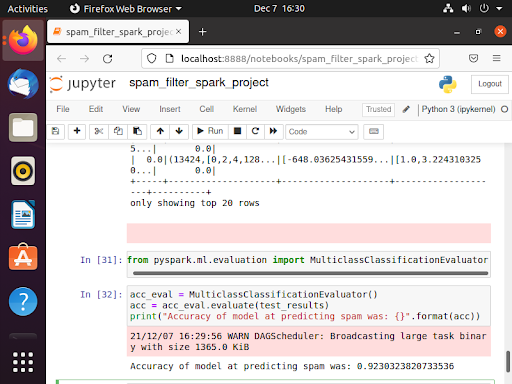
After transforming the emails into features, I used the Naive Bayes models to classify my results.
The accuracy is 92.3% in the testing dataset which is good enough to filter spam.
Software used: VirtaulBox, Ubuntu, Jupyter Notebook
Packages used: Pyspark, Spark MLlib
Wechat ID:
jasonfangmagic