In this project, I worked for a financial company that provides loans to its customers.
The company receives leads from some peer-to-peer (P2P) agencies and the applicants are going to finish their applications on the company website. In the end, they need to
make an E-Sign submit their applications and then they will be evaluated by the company for
the next step. The purpose of this project is to identify what kind of people are likely not
to finish the application so that the company can take some measures to encourage them to finish the
process.
Exploratory Data Analysis
I always do exploratory data analysis before I start building a model. There is a Chinese saying "Sharpening your ax will not delay your job of chopping wood"
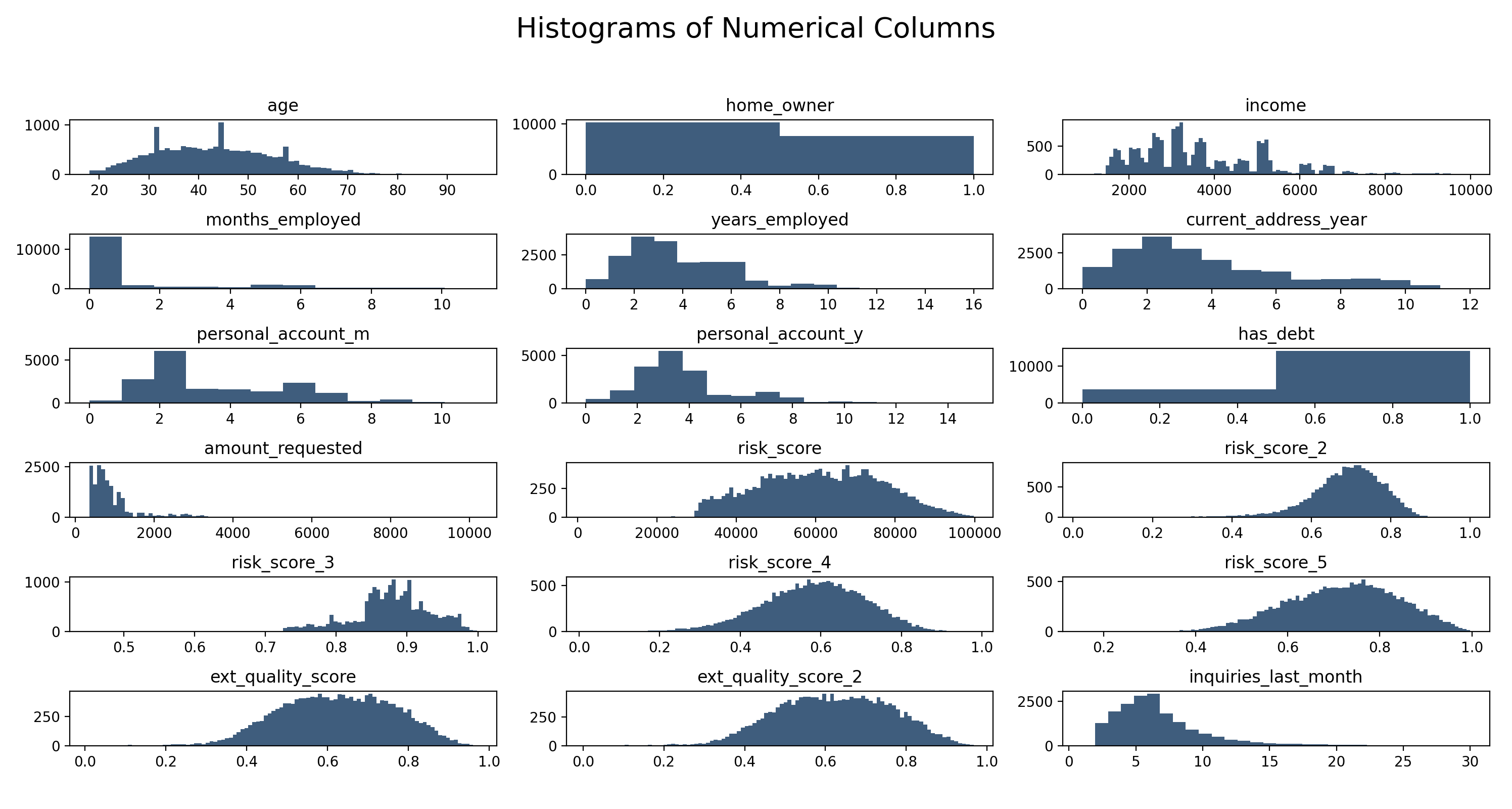
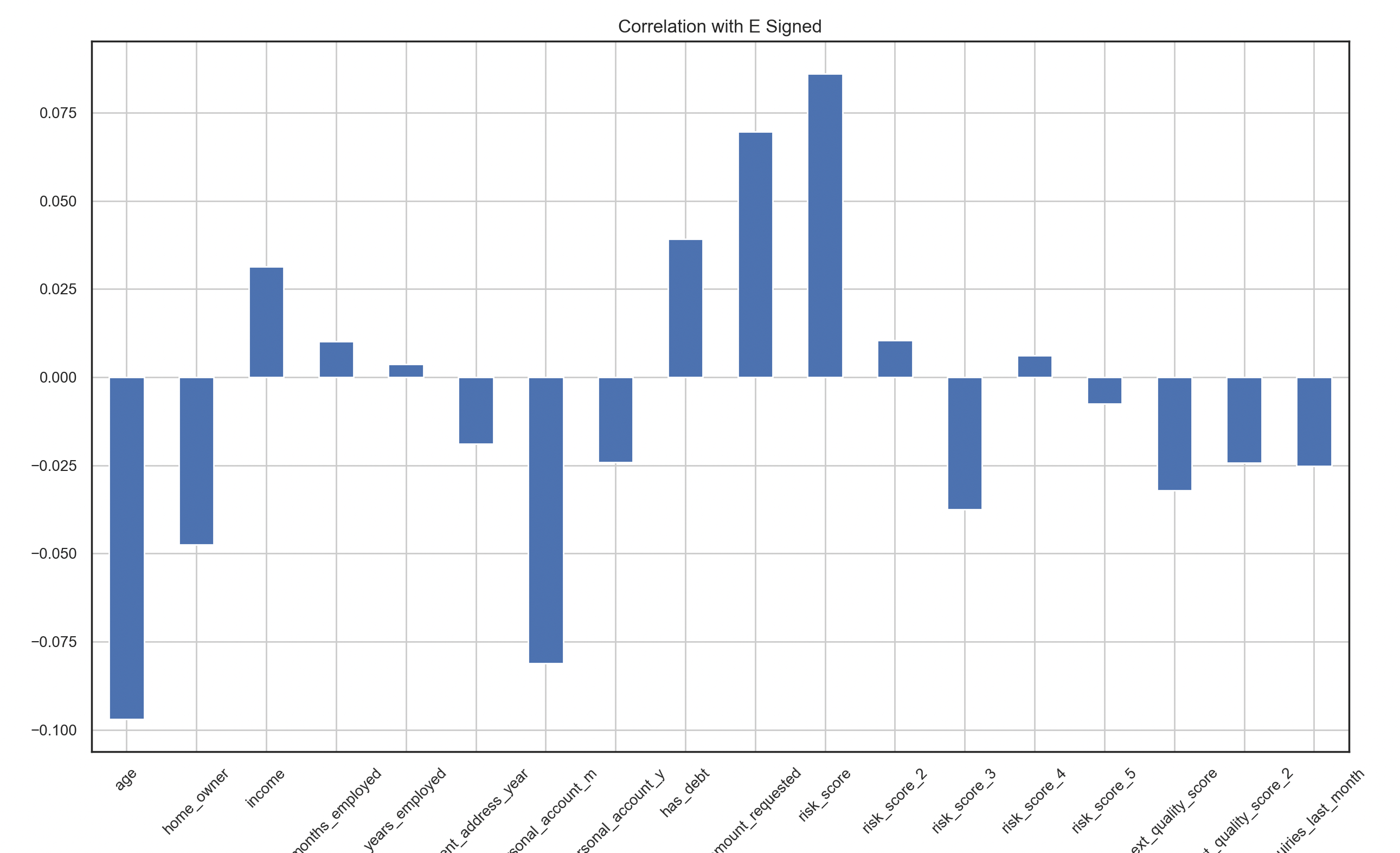
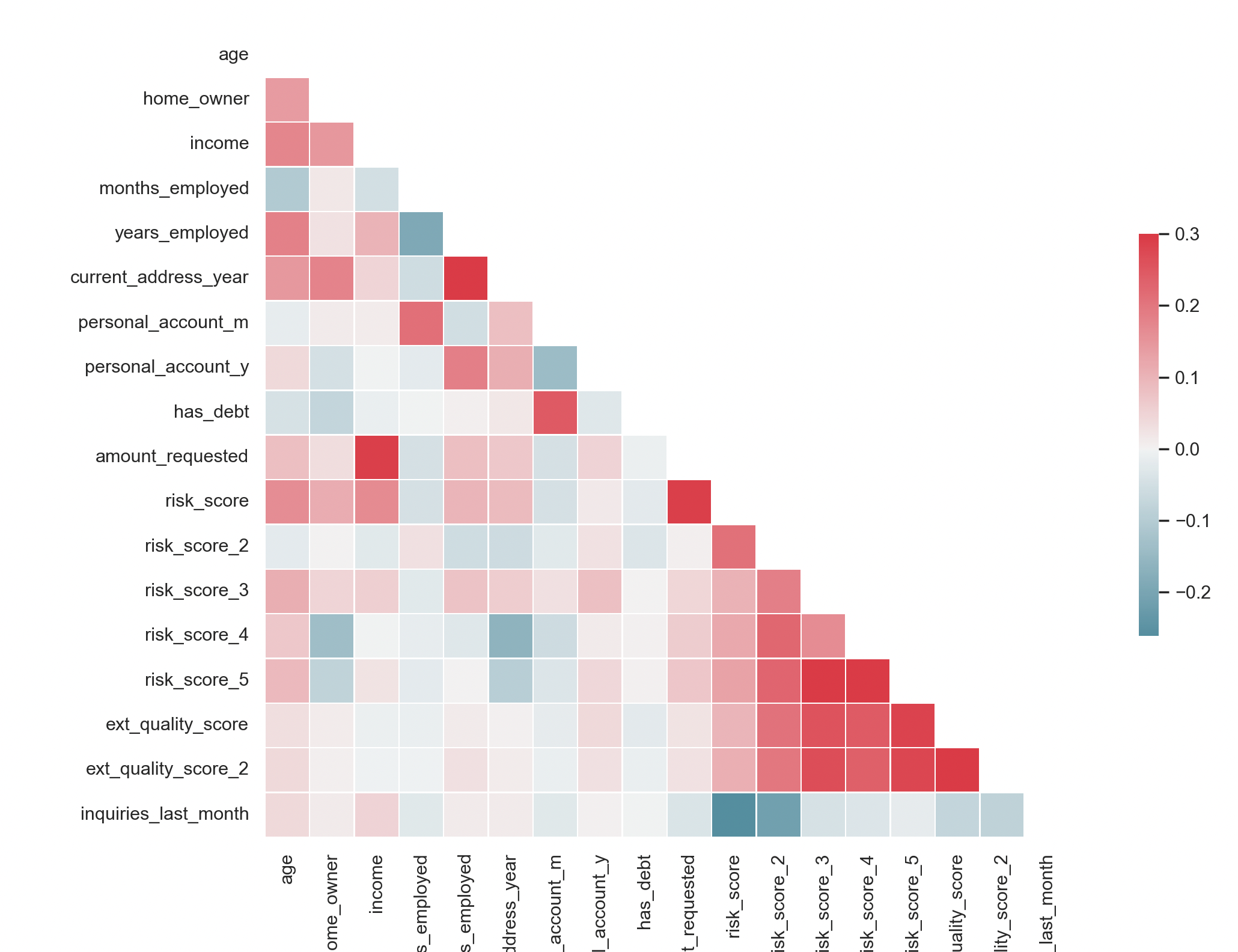
It's always good to create some histograms for the numerical features. Also, the correlation bar chart and matrix are
very helpful for us to find out some findings and problems.
First of all, in the histograms, I found out one interesting chart, which is the "month employed". Many people answered
0 in for this question. It's very unlikely that most people work for exactly 1 year or 2 years.
Secondly, people who have higher risk scores tend to finish the application because I haven't
done feature scaling here. From the correlation matrix, we could see that those risk scores are positively
correlated.
Last but not least, we see these correlations might not be representative if we
use non-linear regression later on, but these charts still give a general idea of the dataset.
Knowing your dataset is very important to data scientists.
Models
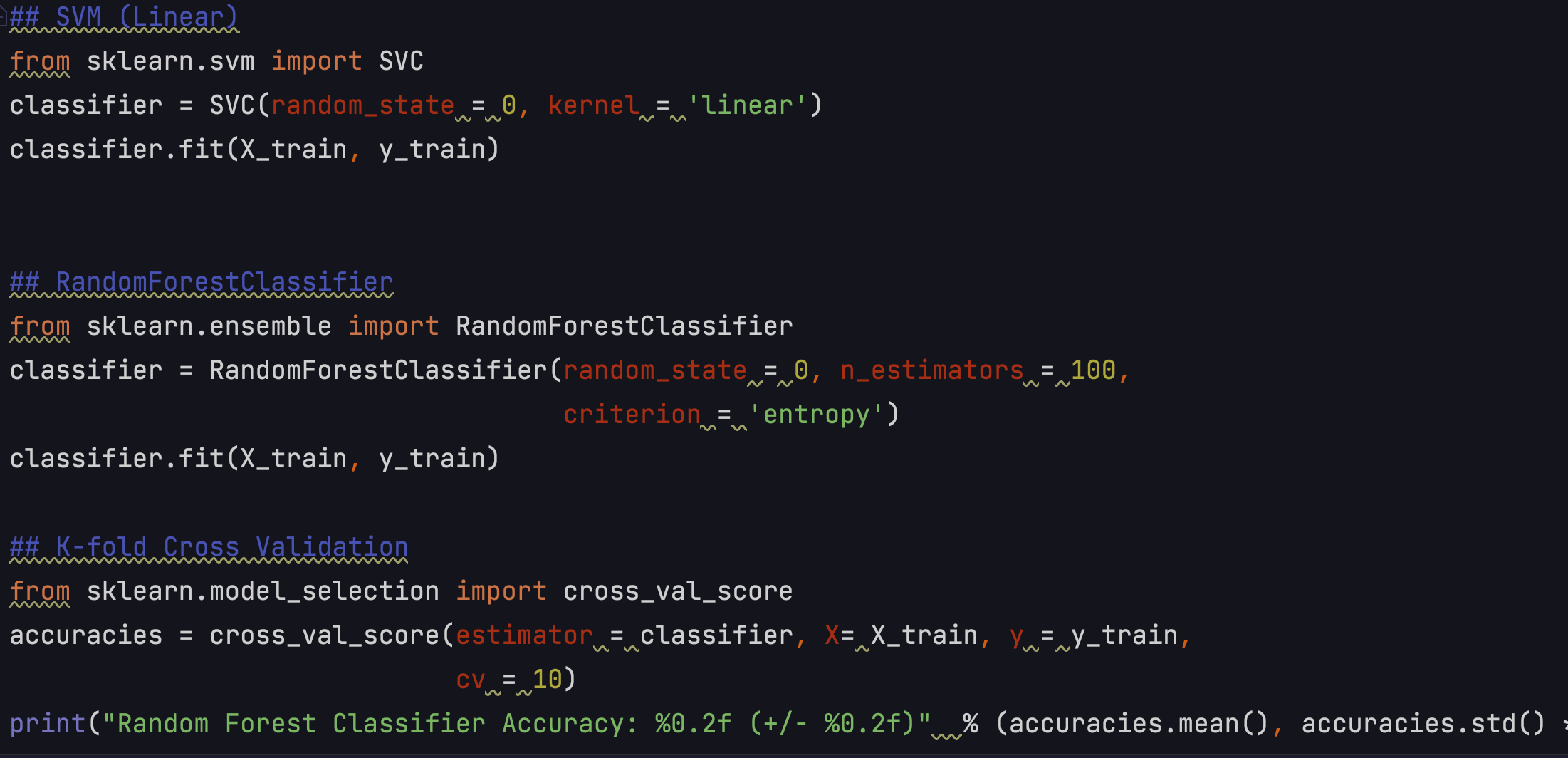
I had tried many classification models, such as SVM, Random Forest, KNN, ANN, and so on.
The random forest model outperformed other models with a 61% accuracy, so I decided to apply grid search to find
out the best parameters for this model.
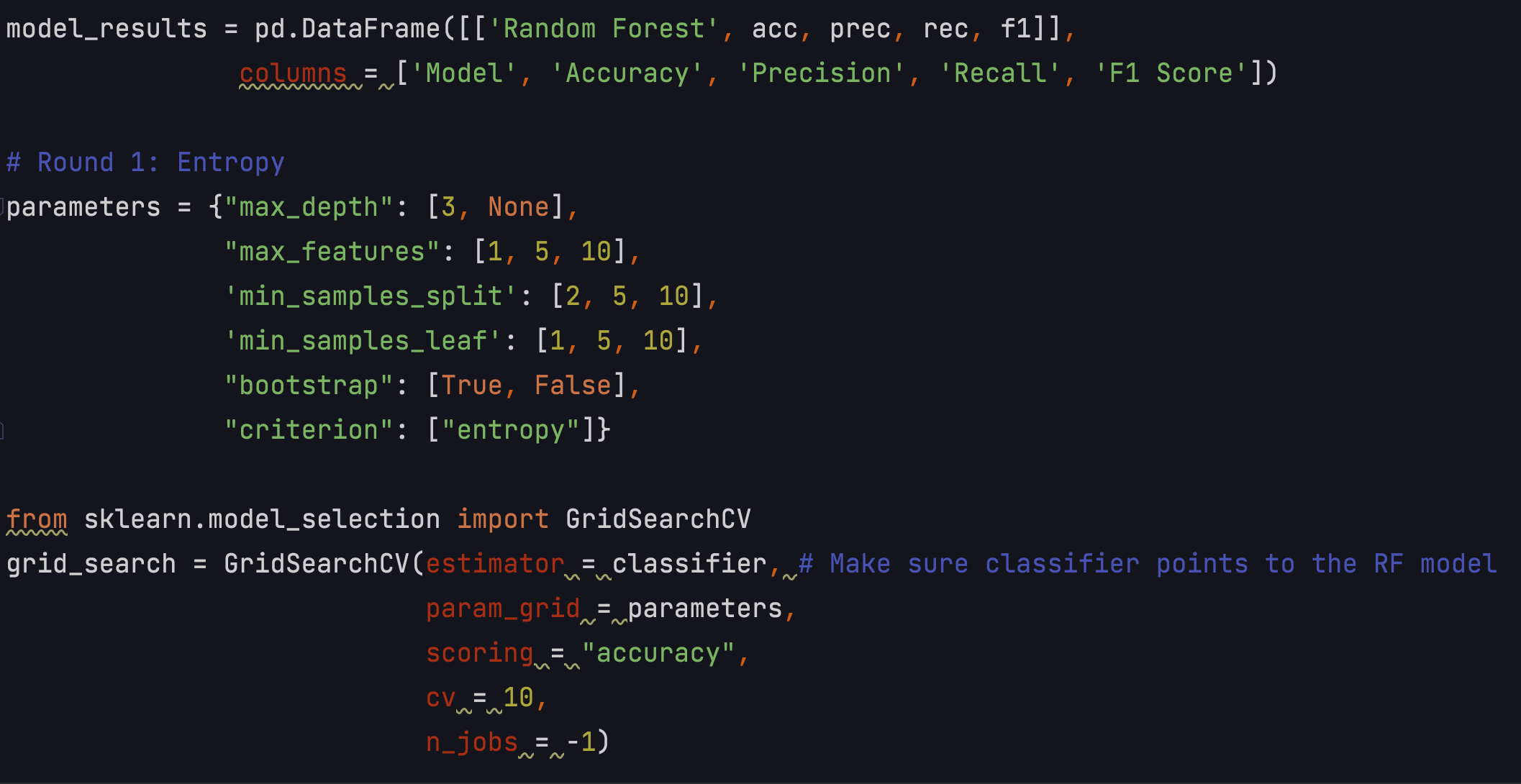
Model Tuning
I tried to tune many parameters for the random forest model, trying entropy and Gini and some other parameters.
It took me more than 11 minutes to tune the model, even though it's a small dataset with relatively few parameters.
The best random forest model got a 63.45% accuracy.
Last Thoughts
I could've tried to tune more parameters, but it would take a lot of time.
The model tuning did not give a drastic increase in terms of accuracy.
Is it worth it? My answer is yes.
Even with just a 1% increase, it could generate a huge amount of revenue if we have a large dataset.
Also, if a classification model were to be used in a self-driving car, 1% could help the car make the correct
decision and save lives.
Software used: Python
Packages used: Sklearn,Seaborn