This is a preprocessed dataset. There are 28 features not interpretable because the personal information of our customers has been transformed and kept anonymous.
The "Class" feature is whether customers have been defrauded or not, 0 = no, 1 = yes.
Undersampling and Oversampling
This dataset contains more than 280,000 observations, but only about 400 people have
been defrauded, which just accounts for 0.14% of the dataset. If we just simply predict
all people having no fraud risk, we would get a 99.86% accuracy.
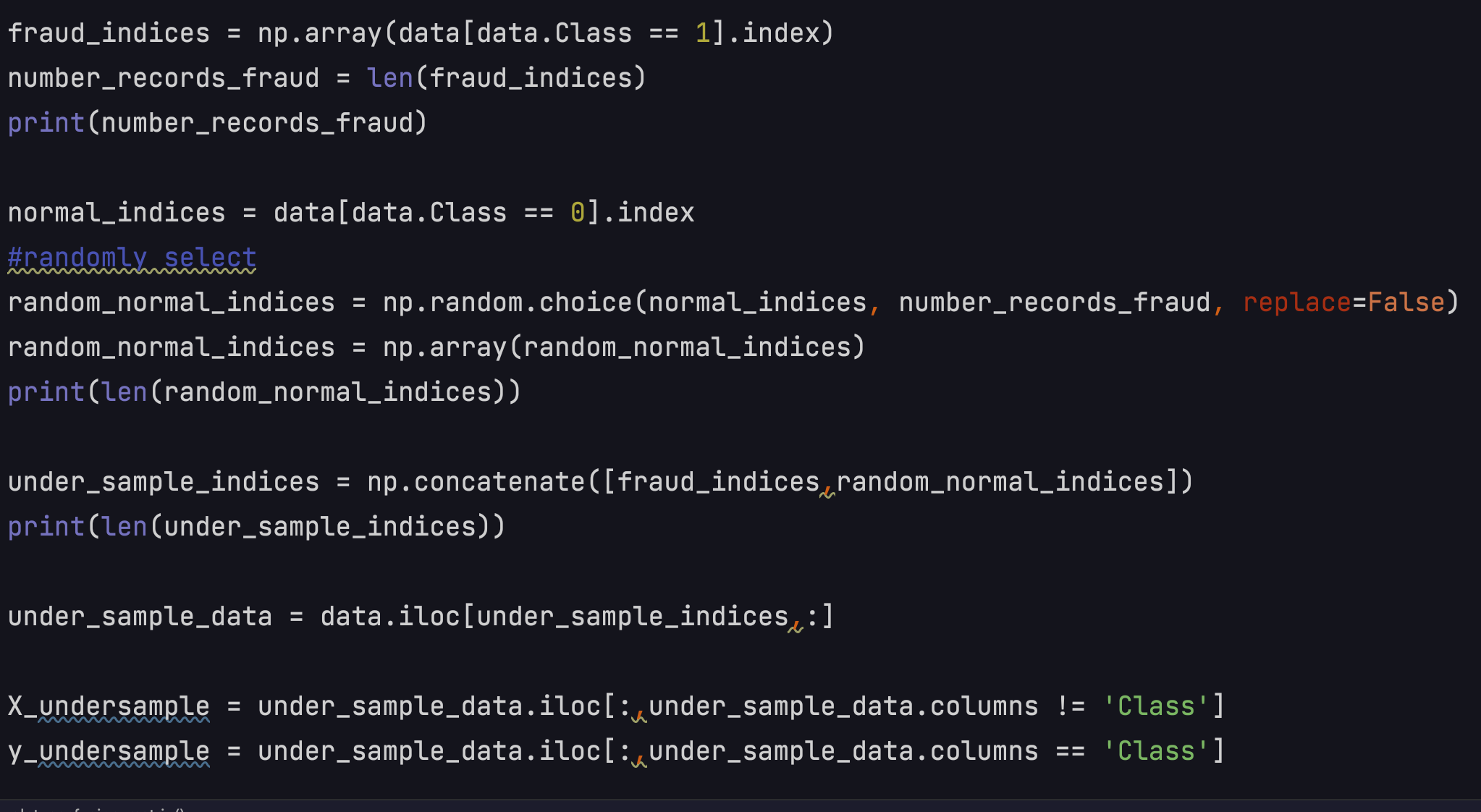
To avoid this situation, I applied undersampling and oversampling to the dataset.
Undersampling is just only keeping 400 people who were not defrauded.
Oversampling is creating 280,000 more defrauded data to match the other class. I used SMOTE
oversampling this case.
Models
I tried many classification models and I decided to use Artificial Neural Network.
Models
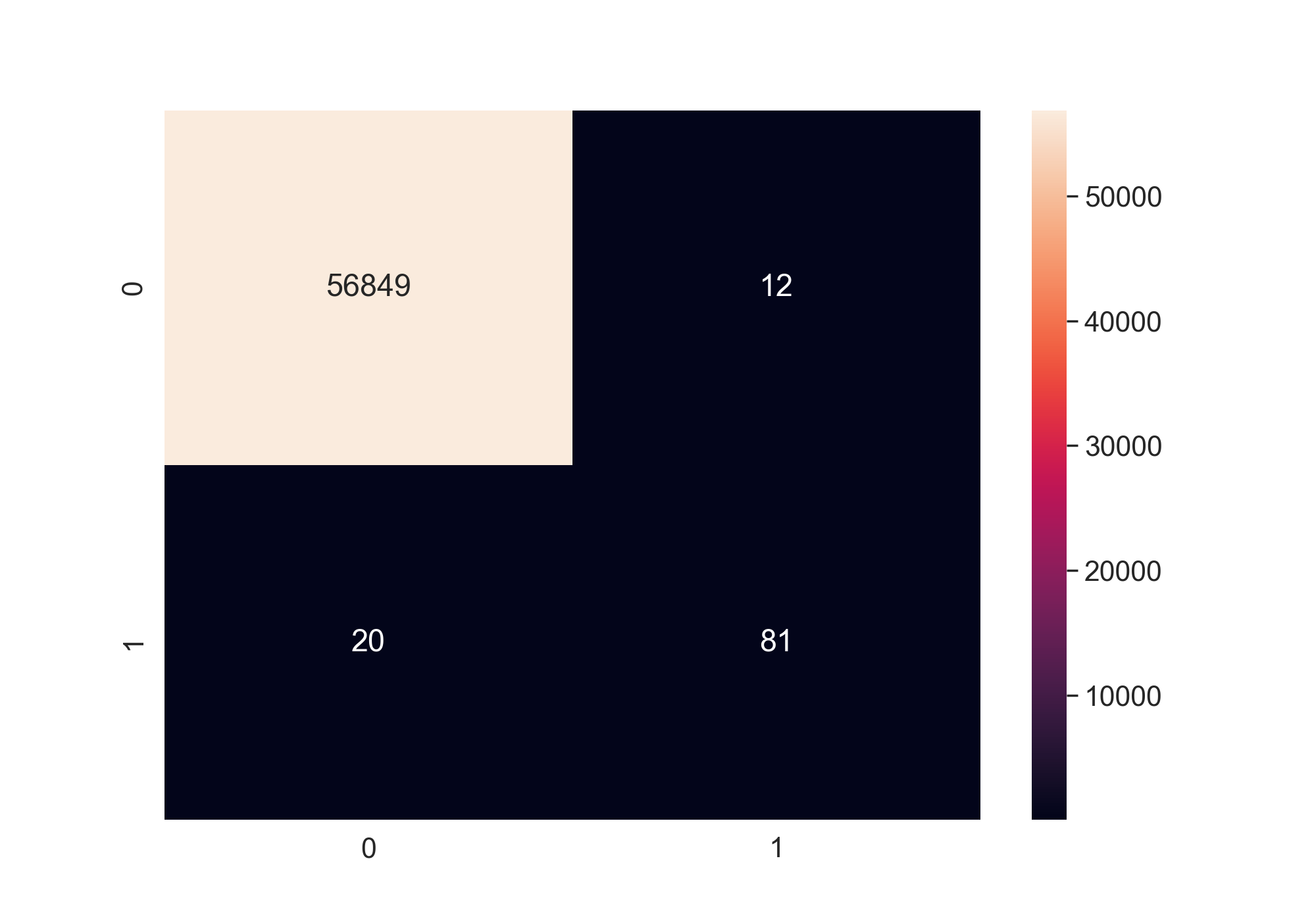
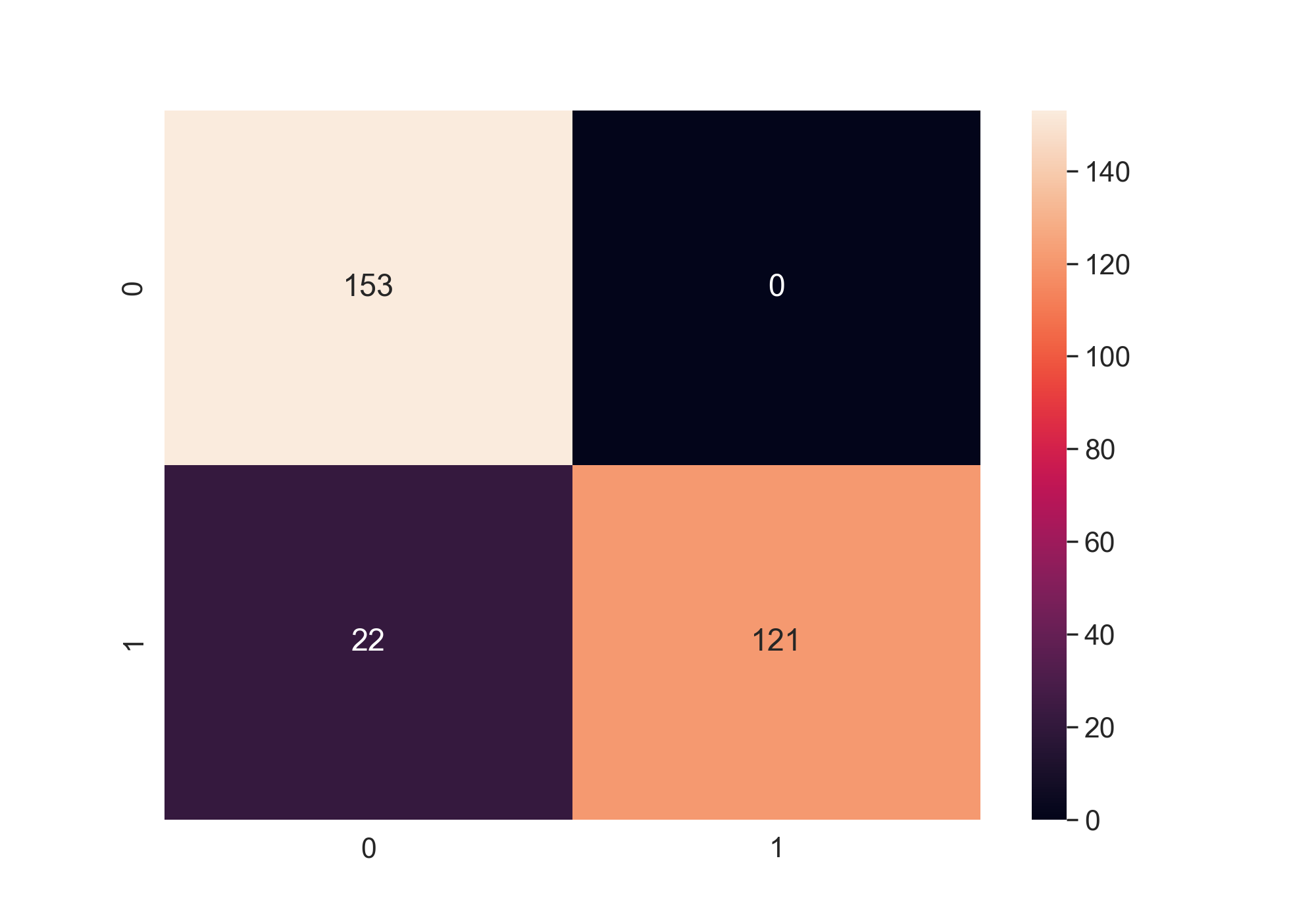
Confusion Matrix
These are two confusion matrices for oversampling and undersampling respectively.
The accuracy of the model is 0.9994, which is good enough for fraud detection. Also, the
type 2 errors are not a lot.
Last Thoughts
What's the ultimate goal for data scientists to create a model? People are obsessed with numbers. They want to have
high accuracy, F1 Score, 0.05 P-value, and so on. In the fraud detection case, if you just simply
guess no fraud at all, you would get a 99.86% accuracy. The number is not the goal.
Data scientists are not cheap. The ultimate goal for data scientists is to create value for
the company. Everything you do should back into short-term value or long-term strategic initiatives.
Knowing the business problem is very critical for data scientists before they start building the model.
Software used: Python
Packages used: Sklearn, Seaborn, Tensorflow, Keras, imblearn