Building ETL pipelines should be data engineers' jobs. While as a data scientist, it's also necessary to
know the fundamental ideas of data pipelines. In this project, I choose a public dataset from Deutsche Börse Public Dataset.
By using AWS S3 and python, I'm able to extract the data from the original AWS S3 bucket and transform the data, then load the data
to my AWS S3 bucket.
Project Task
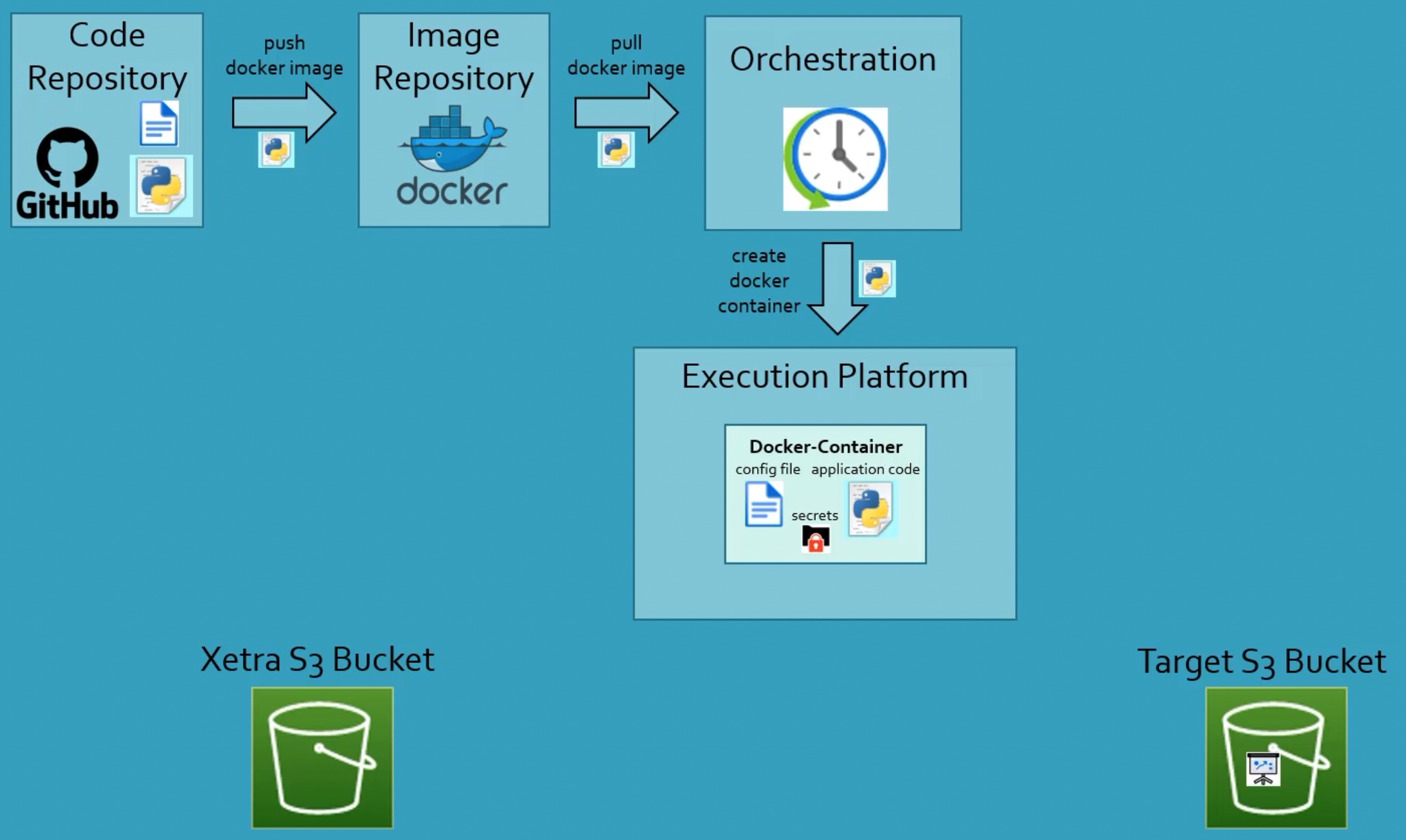
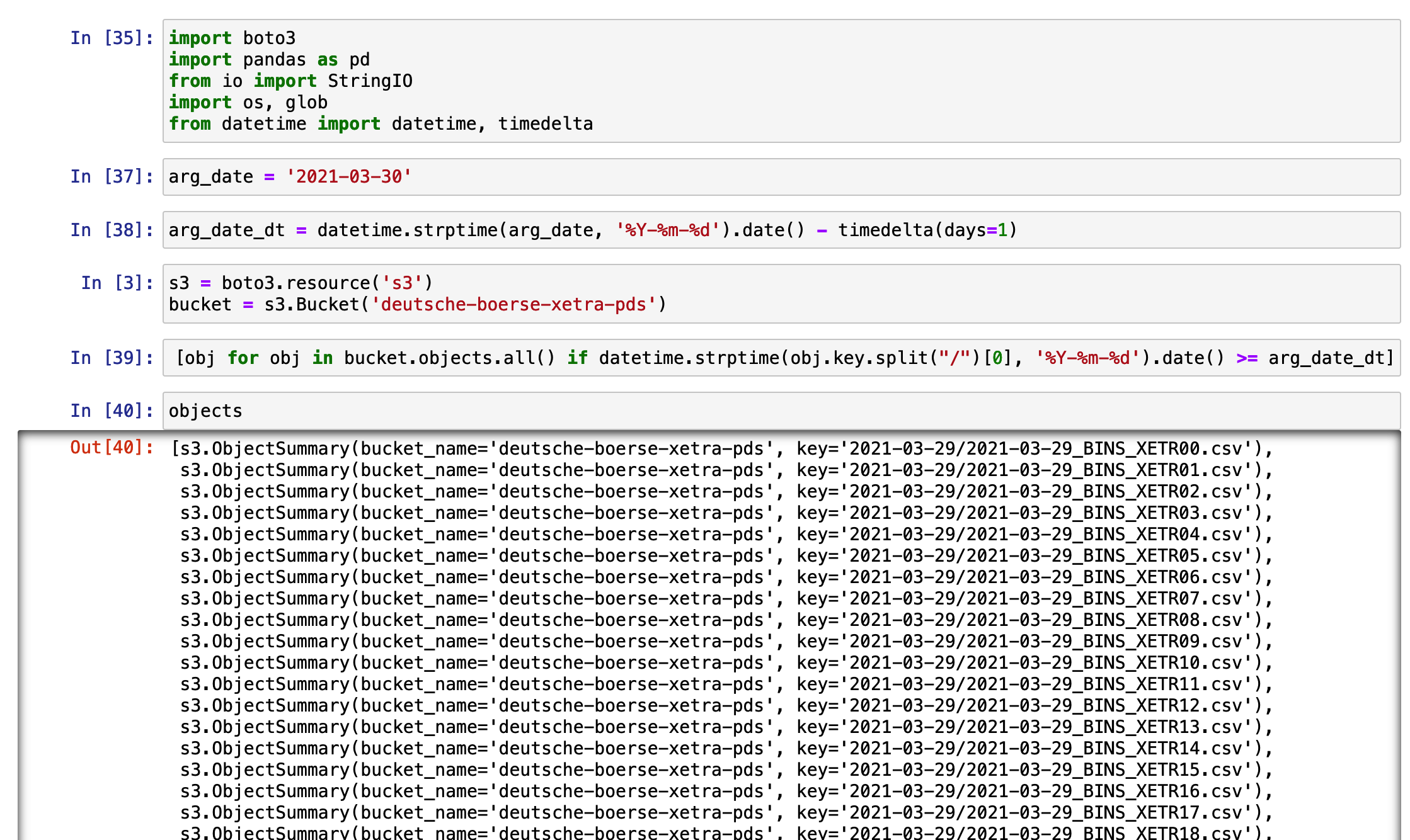
The images below are the overview of the dataset and the production environment. The task of this project is to extract the data from the Xetra S3 bucket to my target S3 bucket. A scheduler should be able to run the job routinely. It could extract the data every week from my
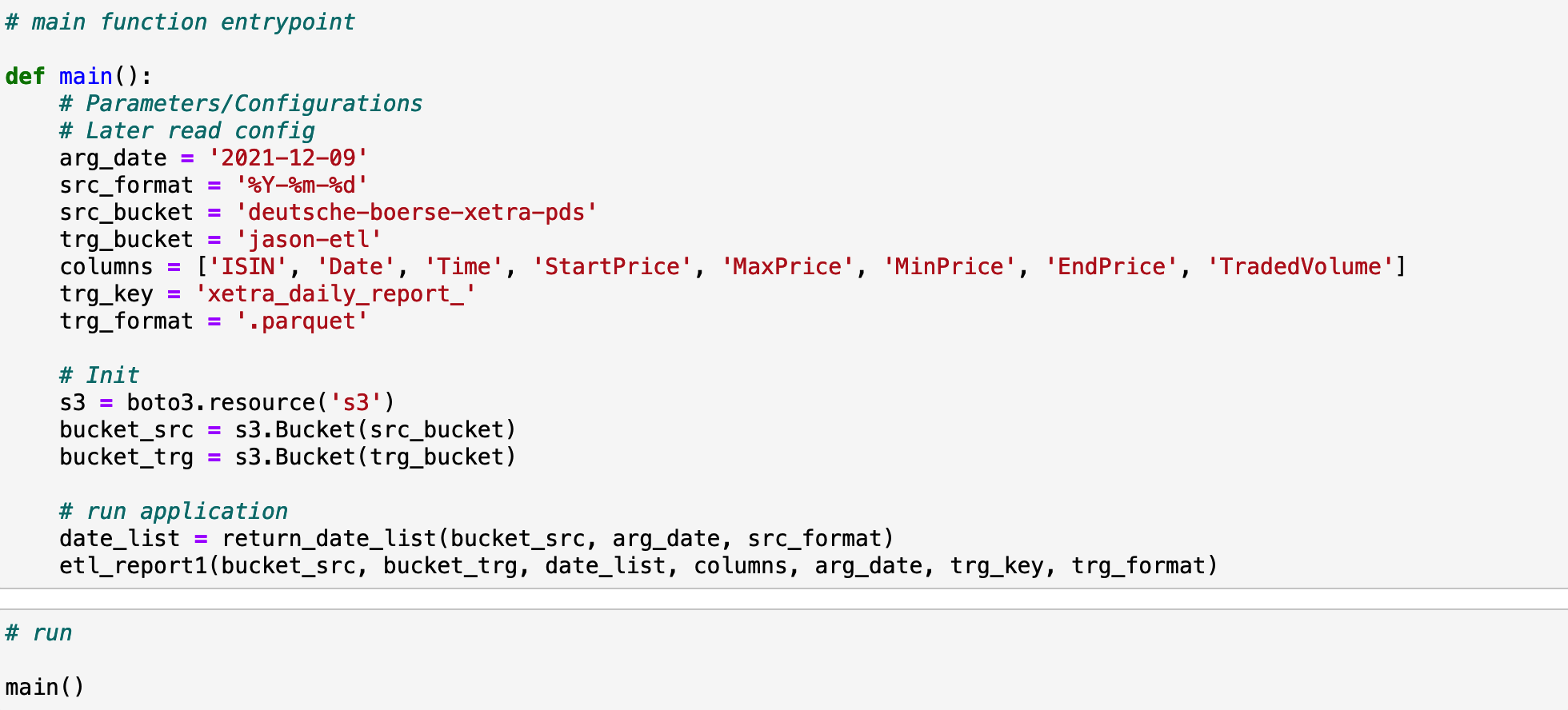
python data pipeline. Here are some requirements for this task:
1. Target format parquet
2. First date for the report as input
3. Auto-detection of the source files to be processed
4. Configurable production-ready Python job
Dataset
The Deutsche Börse Public Dataset (PDS) project makes near-time data derived from Deutsche Börse's trading systems available to the public for free.
This is the first time that such detailed financial market data has been shared freely and continually from the source provider.
You can access this dataset on its GitHub page, Deutsche Börse Public Dataset (DBG PDS).
The data is uploaded into two Amazon S3 Buckets in the EU Central (Frankfurt) region: Xetra data and Eurex data.
In this project, I used the Xetra dataset which stands for exchange electronic trading. This data is provided on a minute-by-minute basis and aggregated from the Xetra engine, which comprises a variety of equities, funds and derivative securities. The PDS contains details for on a per security level, detailing trading activity by minute including the high, low, first and last prices within the time period.
Set Up AWS
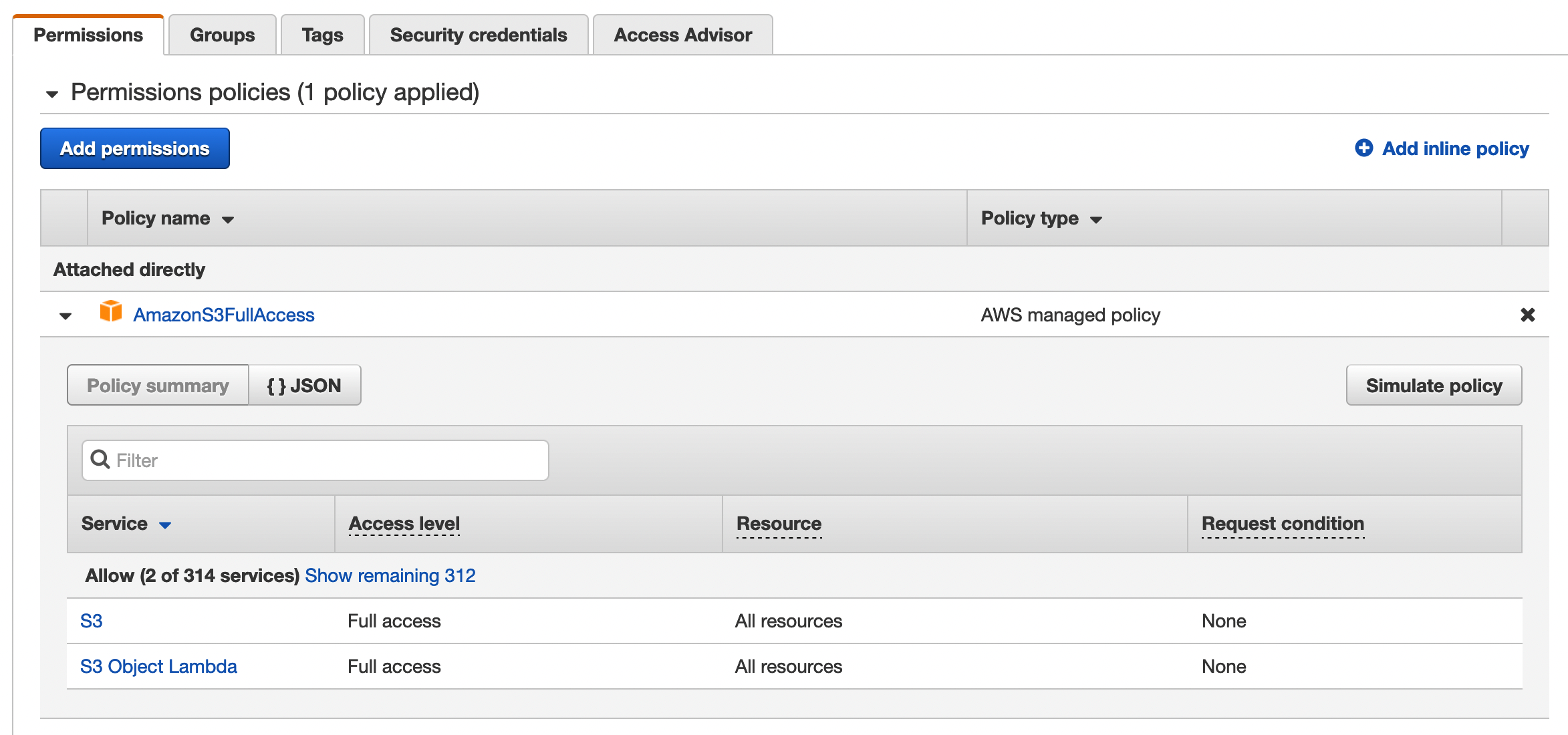
Even though it's a public dataset, you still need programmatic access, which allows you to invoke actions on your AWS resources either through an application that you write or through a third-party tool.
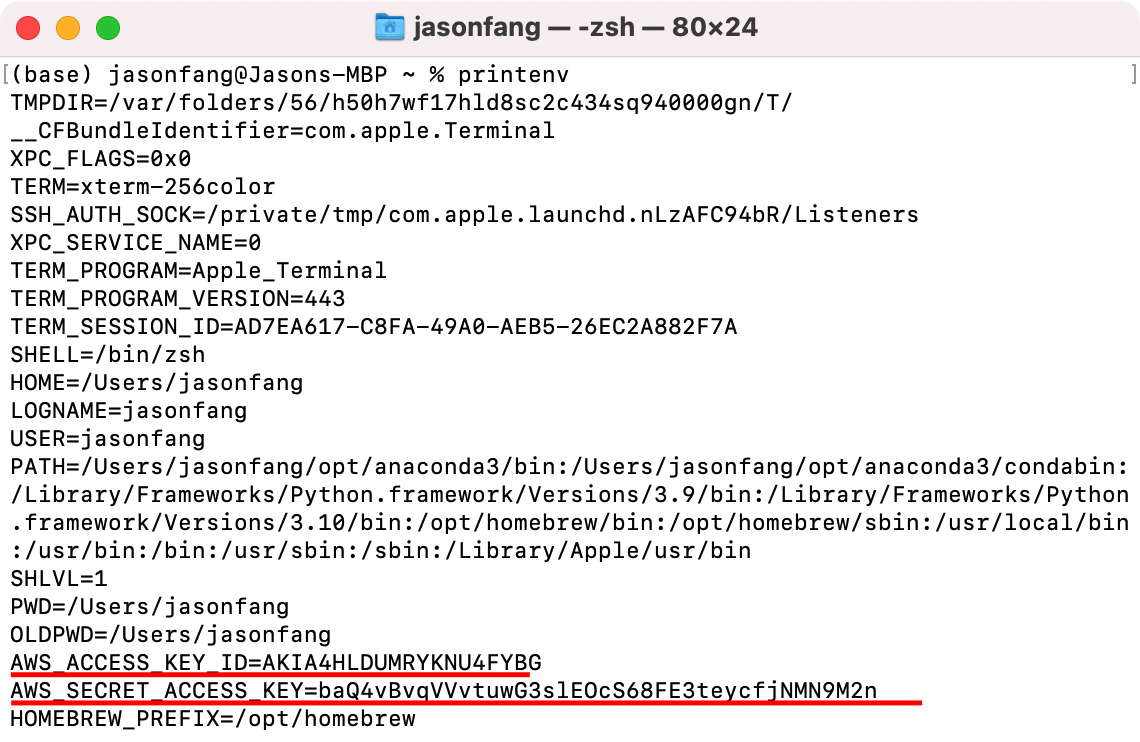
After adding a user in AWS IAM, I add the AWS_ACCESS_KEY and AWS_SECRET_ACCESS_KEY to my environment variables.
Two packages, awscli and boto3, are required to connect AWS and Python,
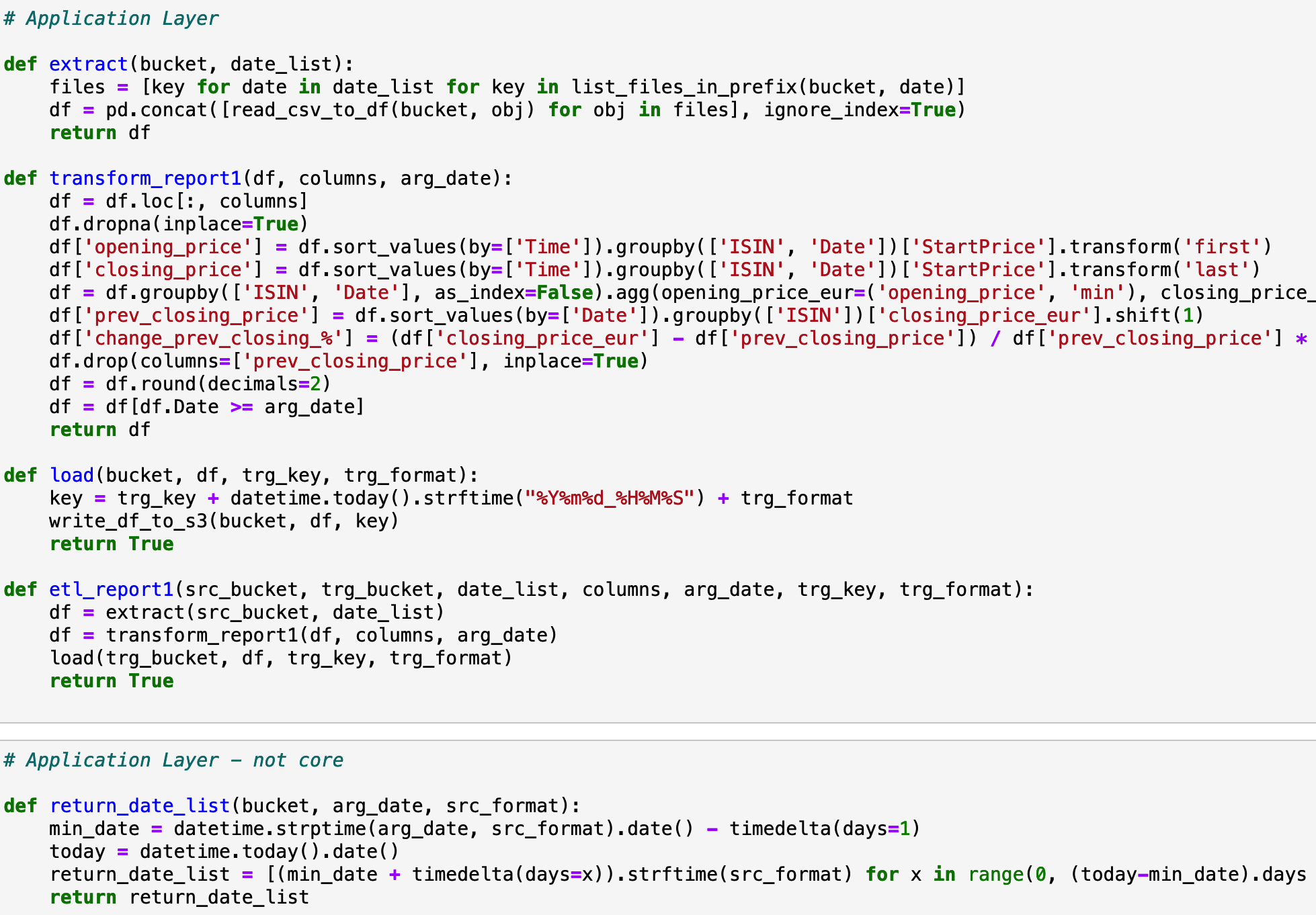
Data Transformation And Argument Date
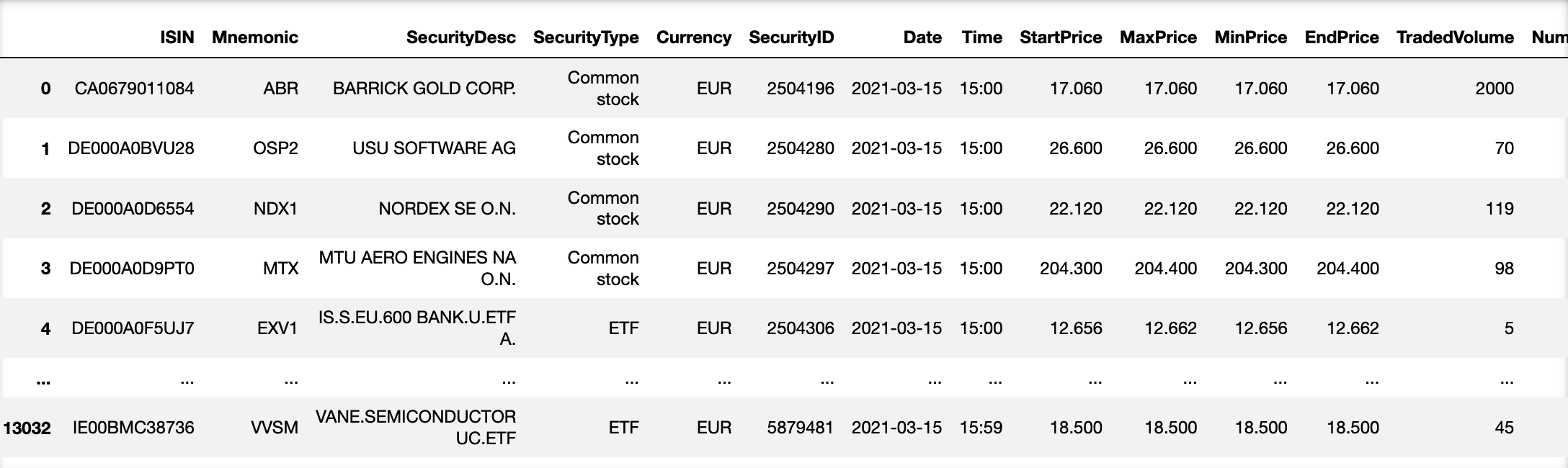
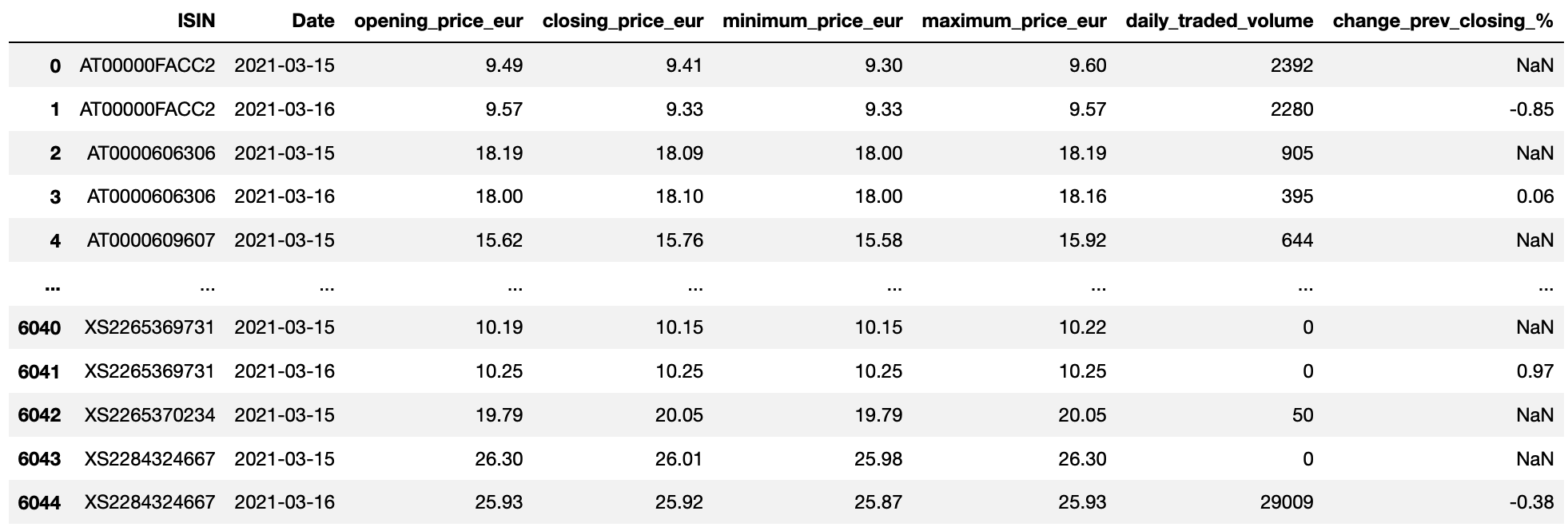
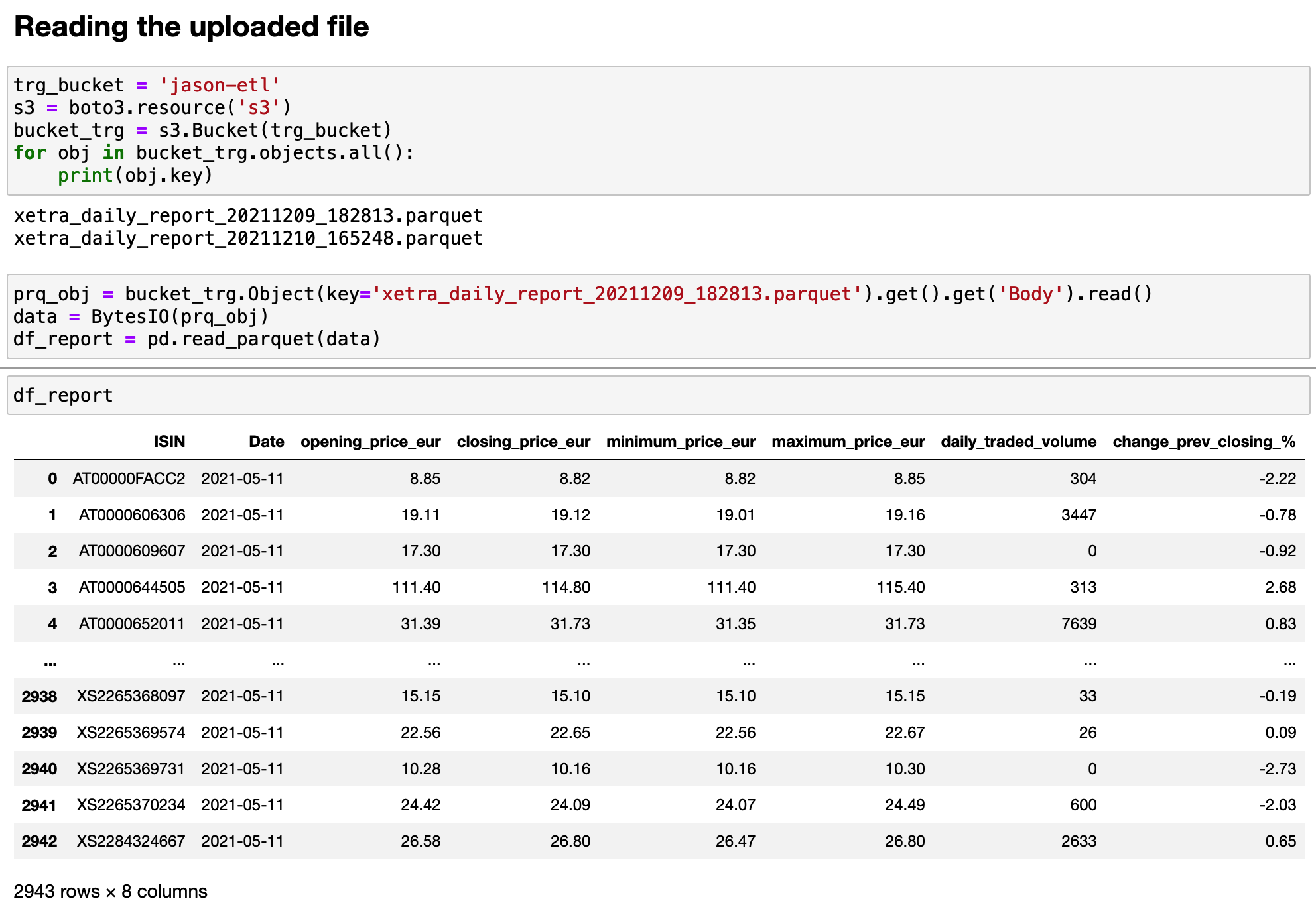
Data transformation in this project is fairly easy. By using groupby functions, I get the final result in the
image below. Only extracting several useful columns makes the data clearer. However, data manipulation is not the key point of
this project. March 30th, 2021 is set as the first date of the stream.
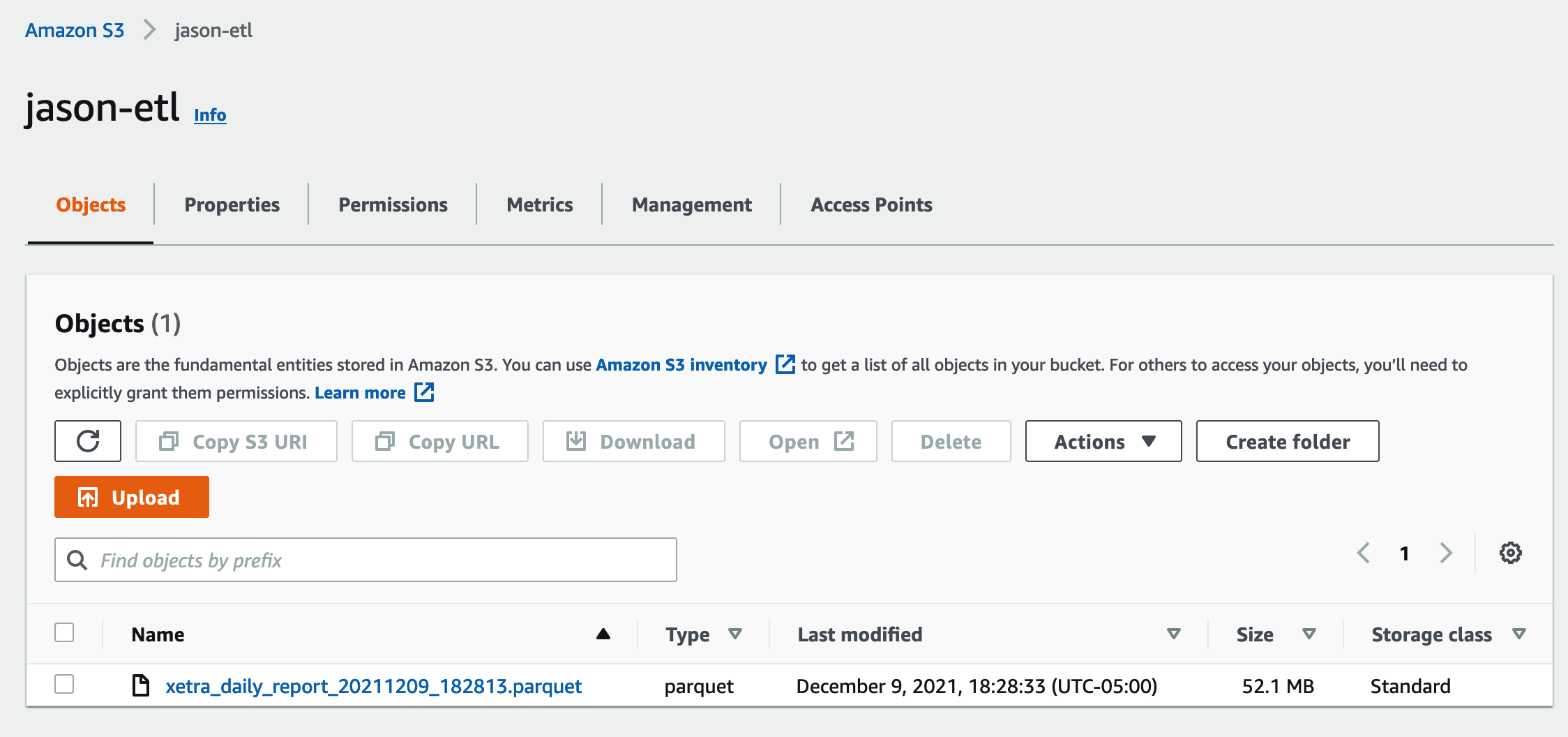
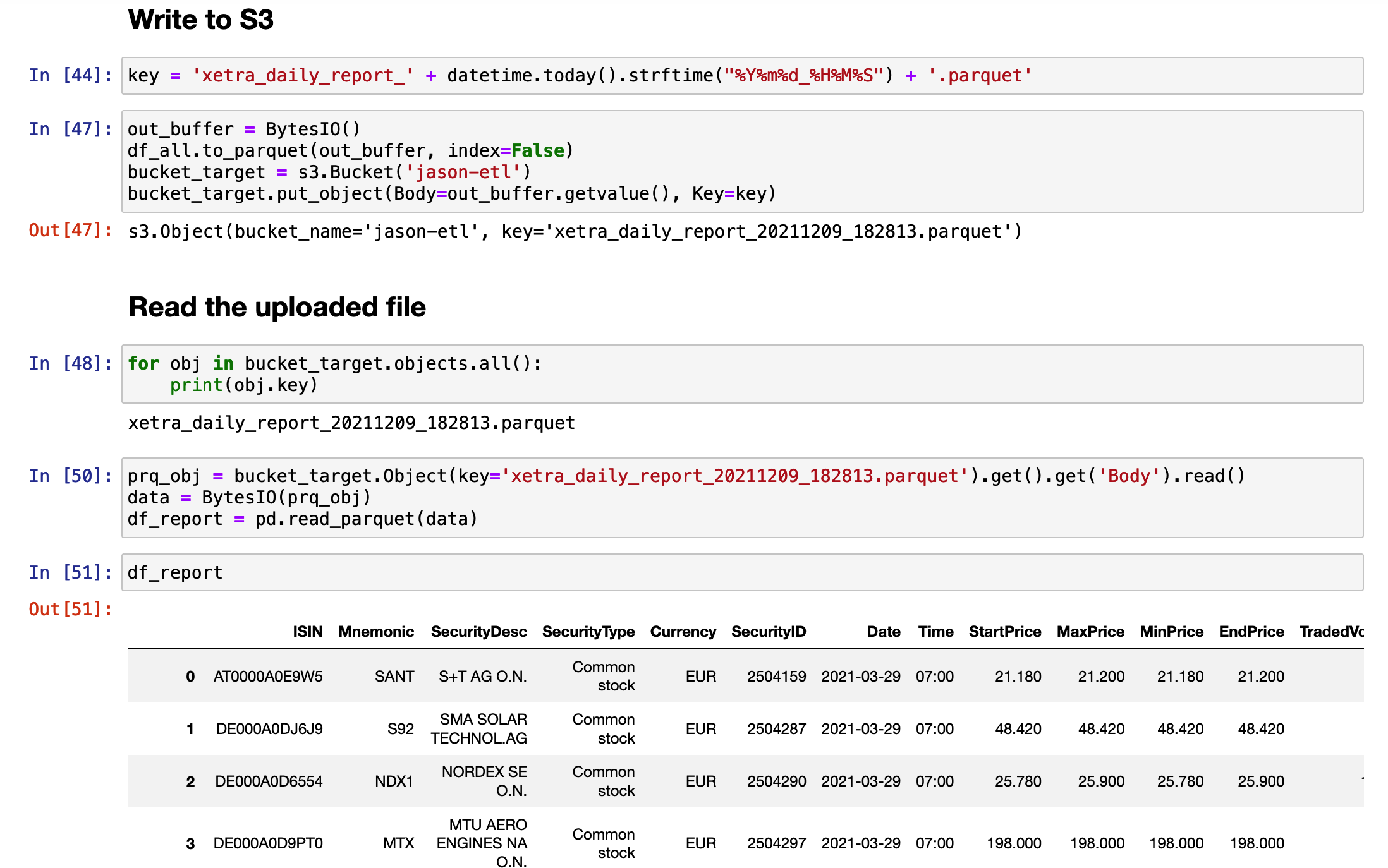
Save Data to AWS S3
To save the data to AWS S3, I have to install a pyarrow package first. Then I create a new bucket to store the data.
The format of this dataset is parquet.
Functional Programming
To write clean code, two methods, functional programming and object-oriented programming are often being used.
In this project, I used functional programming to write several functions to extract, transform and upload the data.
Production
Ask data engineers. I'm a data scientist. Thank you.
Software used: Python, AWS S3