People create tons of models every year, but 85% of them are useless. As a data scientist, I want to create values for my company and the world. In practice, good models can save lives and bad models can cost lives.
This is an example of how I use classification models to identify malignant and benign for breast cancer.
Usually, a 90% accuracy model is good enough, but it's not good enough for identifying cancer. Even though this is just an example and no one would use my models, I still treat this example seriously. That's what data scientists are about to do in the future, changing the world.
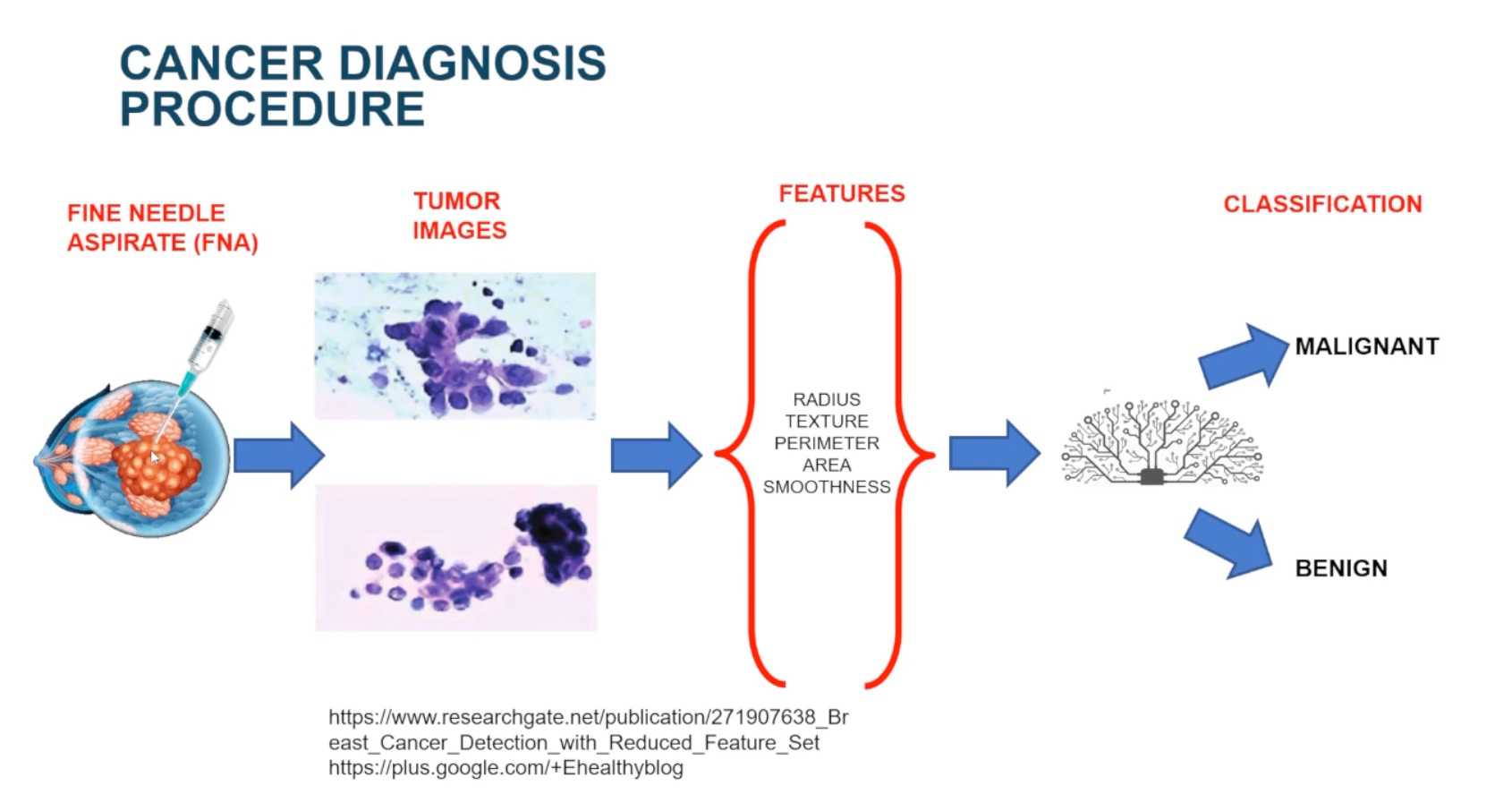
Cancer Diagnosis Procedure
Before I get started, I want to know the cancer diagnosis procedure. Understanding the problem is very important for data scientists. We not only want to build models, but also we want to solve real business problems.
The chart below shows the procedure of identifying malignant and benign for breast cancer.
People create tons of models every year, but 85% of them are useless. As a data scientist, I want to create values for my company and the world. In practice, good models can save lives and bad models can cost lives.
This is an example of how I use classification models to identify malignant and benign for breast cancer.
Usually, a 90% accuracy model is good enough, but it's not good enough for identifying cancer. Even though this is just an example and no one would use my models, I still treat this example seriously. That's what data scientists are about to do in the future, changing the world.
Data Preprocessing
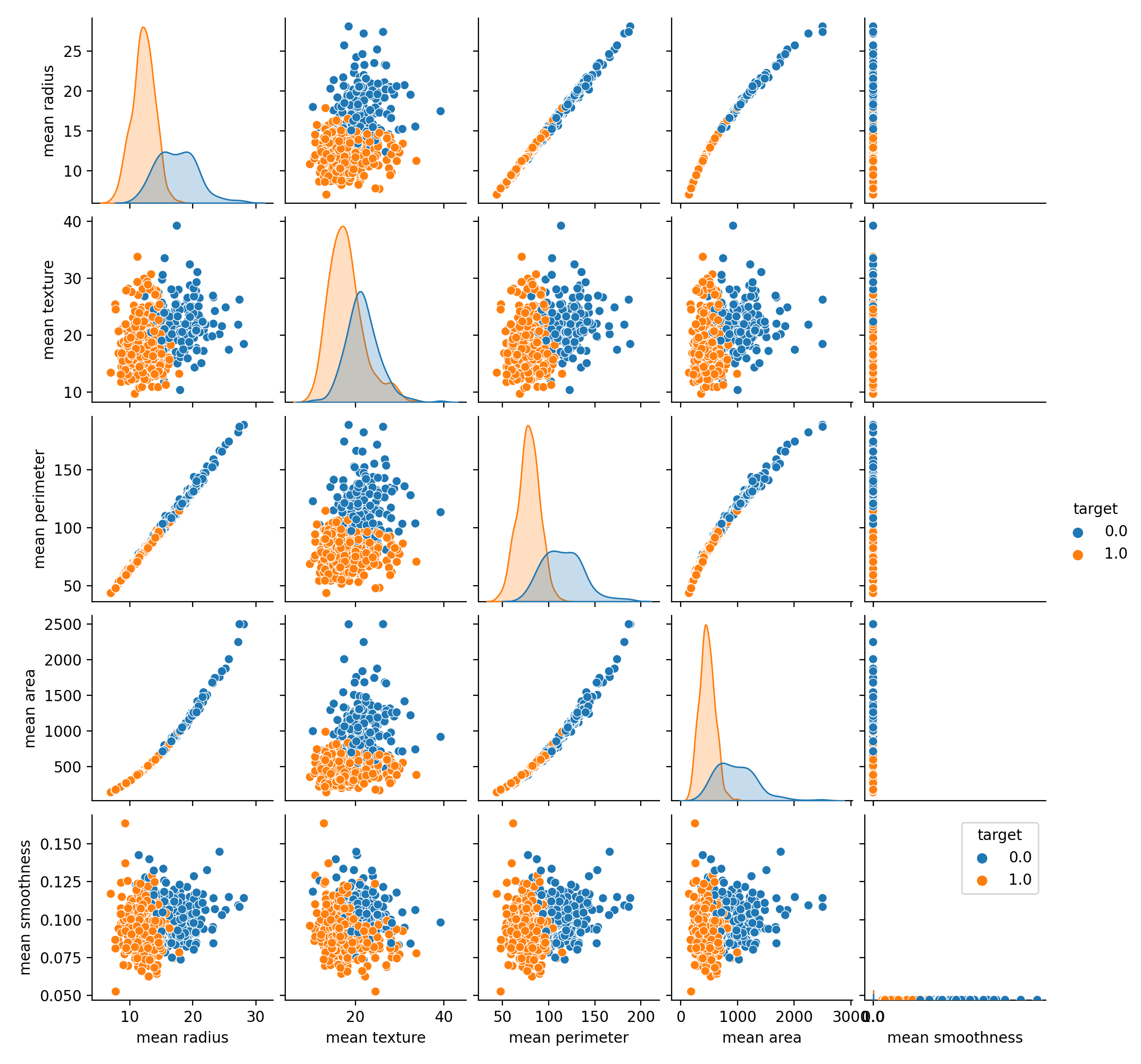
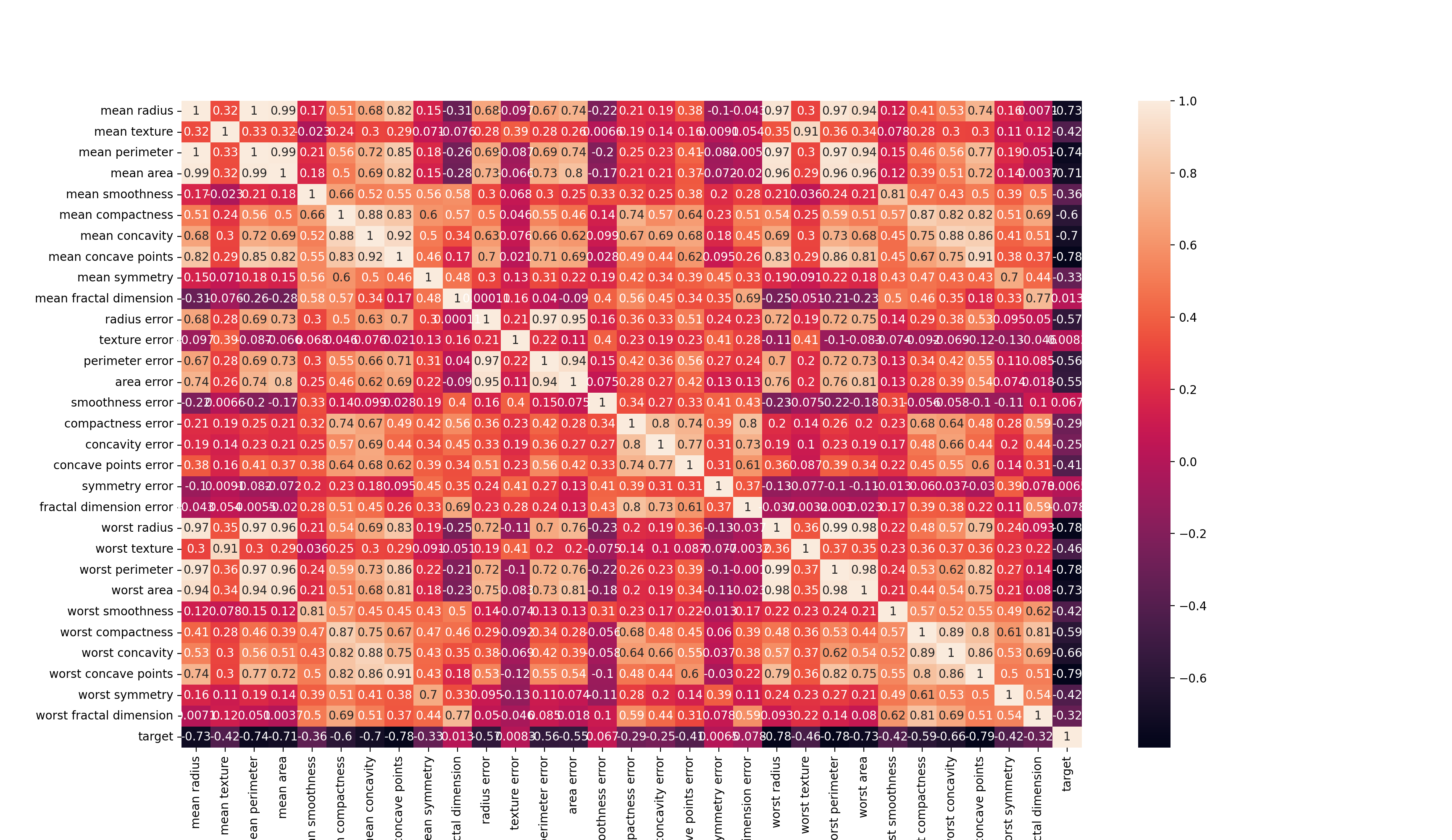
I usually look at the plots of my data before I start creating models. This time, I used
seaborn to generate a heatmap and a pair plot to see the relationship between the features and target.
It looks like using the SVM classifier is the best choice in this case.
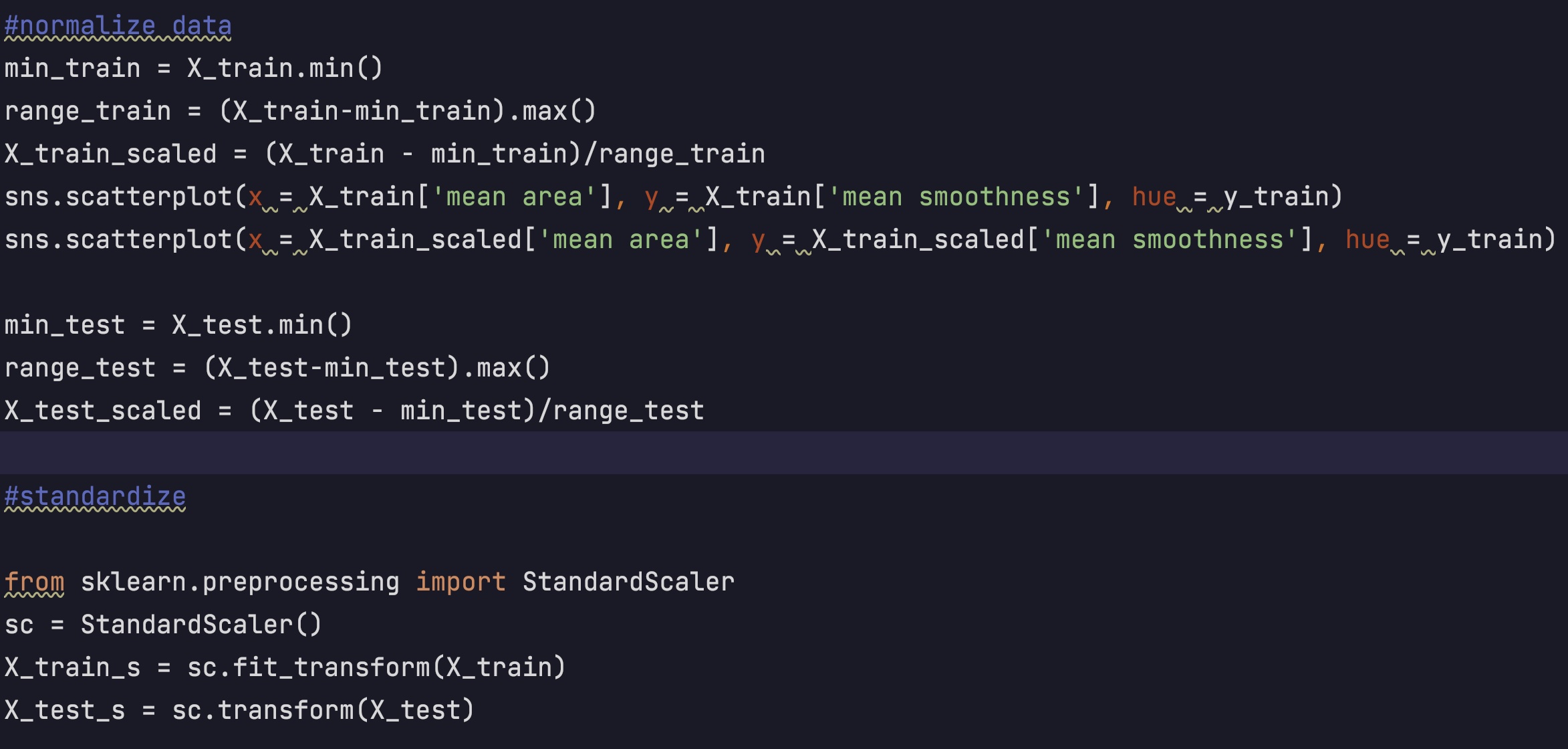
Then I tried to standardize and normalize the dataset.
Classification
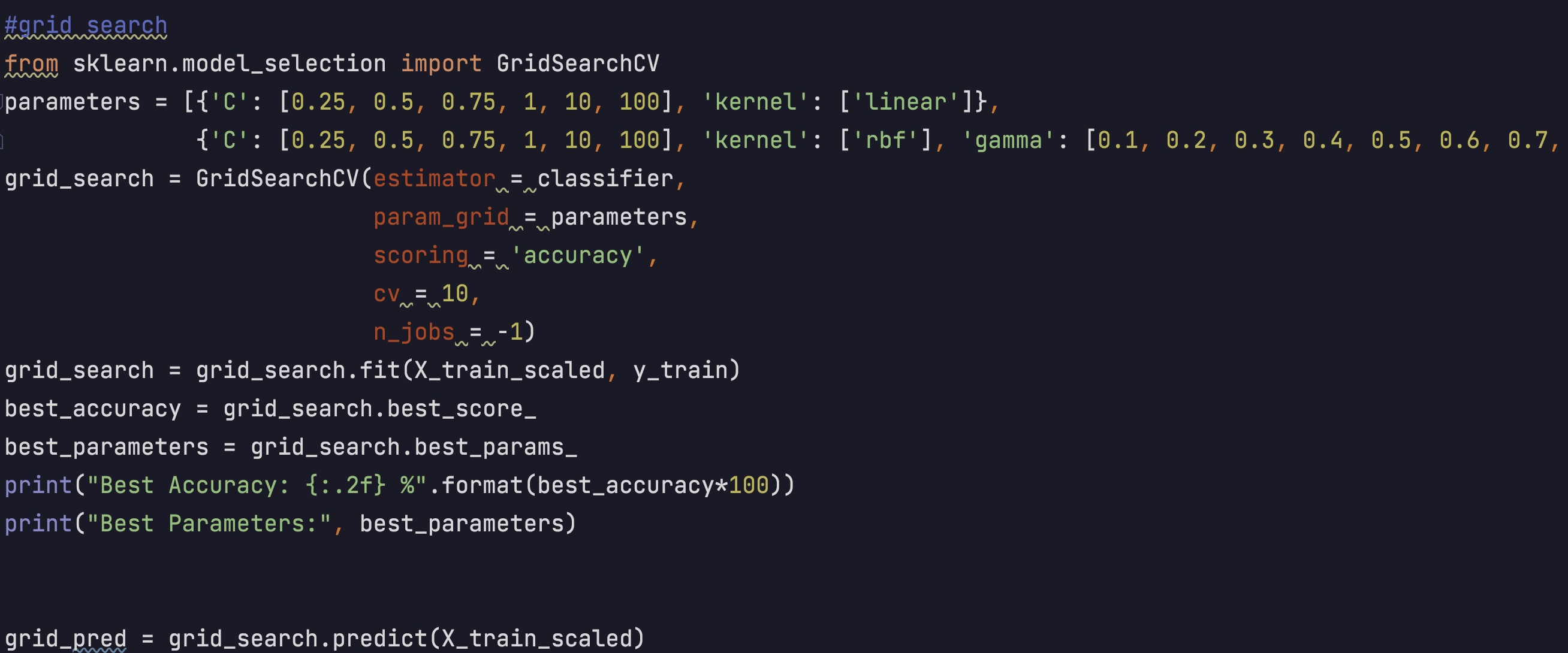
Don't use the default values. I used grid search to tune the model. Then I found out
that the best accuracy is 98.25 % by using C = 10, gamma = 0.3 and kernel = rbf.
Overall, this is just an example of how I built my classification models. This model could be further improved
and I could try other models as well, such as KNN, random forest and XGBoost, and so on.
Software used: Python
Packages used: sklearn, seaborn, GridSearchCV, numpy, pandas